Microservices und Kubernetes¶
Kubernetes¶
Kubernetes ist eine Software, die hilft, Programme in sogenannten Containern zu organisieren und auszuführen. Diese Container sind wie kleine Pakete, die alles enthalten, was eine Anwendung benötigt, um zu laufen. Kubernetes kümmert sich darum, wie diese Container gestartet, gestoppt und auf verschiedenen Computern verteilt werden. Es ist besonders nützlich, wenn man viele solcher Programme gleichzeitig betreiben möchte, weil es hilft, alles ordentlich zu organisieren und sicherzustellen, dass sie immer laufen, selbst wenn mal ein Computer ausfällt. Kurz gesagt, Kubernetes macht es einfacher, viele Programme gleichzeitig im Internet laufen zu lassen.
Die Architektur von Kubernetes¶
Die Architektur von Kubernetes ist in mehrere Komponenten unterteilt, die zusammenarbeiten, um Containeranwendungen zu verwalten. Hier ist eine vereinfachte Übersicht:
Master-Knoten (Master Node):
Der Master-Knoten ist das Gehirn des Kubernetes-Clusters.
Er besteht aus verschiedenen Komponenten, darunter:
API-Server: Das zentrale Steuerungselement, über das Benutzer und andere Teile des Clusters kommunizieren.
Scheduler: Entscheidet, wo Container gestartet werden sollen, basierend auf Ressourcenanforderungen und anderen Faktoren.
Controller Manager: Überwacht den Zustand des Clusters und reagiert auf Änderungen, um sicherzustellen, dass der gewünschte Zustand erhalten bleibt.
Arbeitsknoten (Worker Nodes):
Die Arbeitsknoten sind die Maschinen, auf denen Container ausgeführt werden.
Jeder Arbeitsknoten hat folgende Komponenten:
Kubelet: Ein Agent, der auf jedem Knoten läuft und die Kommunikation mit dem Master-Knoten ermöglicht. Er startet, stoppt und verwaltet Container auf dem Knoten.
Container Runtime: Die Software, die für das Starten und Ausführen von Containern verantwortlich ist, wie Docker oder containerd.
Kube Proxy: Ein Netzwerkproxy, der den Netzwerkverkehr zwischen den Containern im Cluster verwaltet.
Pods:
Ein Pod ist die kleinste ausführbare Einheit in Kubernetes.
Er besteht aus einem oder mehreren Containern, die gemeinsam auf einem Arbeitsknoten ausgeführt werden und gemeinsame Ressourcen und Netzwerkraum teilen.
Diese Komponenten arbeiten zusammen, um Containeranwendungen auf einem Kubernetes-Cluster zu verwalten, sie automatisch zu skalieren, hochverfügbar zu machen und Ressourcen effizient zu nutzen.
Microservices¶
In Kubernetes sind Microservices eigenständige und feingranulare Komponenten einer größeren Anwendung. Analog zum Bild eines Autos repräsentieren sie einzelne Systeme wie den Motor, die Bremsen und das Navigationssystem, die jeweils spezifische Aufgaben erfüllen. Jeder Microservice übernimmt eine klar definierte Funktion, beispielsweise die Verarbeitung von Bestellungen oder die Benutzerauthentifizierung. Kubernetes fungiert als Orchestrierungsplattform, die es ermöglicht, diese einzelnen Komponenten effizient zu verwalten und miteinander zu integrieren, ähnlich der harmonischen Zusammenarbeit eines gut abgestimmten Teams unter der Motorhaube eines Fahrzeugs.
Motivationen für die Verwendung von Microservices auf Kubernetes¶
Skalierbarkeit: Mit Microservices auf Kubernetes können einzelne Komponenten der Anwendung unabhängig voneinander skaliert werden. Das bedeutet, dass, wenn ein Teil der Anwendung aufgrund erhöhter Last mehr Ressourcen benötigt, Instanzen dieses Microservices hinzugefügt werden können, ohne die anderen zu beeinträchtigen. Dies ermöglicht eine dynamische Anpassung der Ressourcen an die Anforderungen der Anwendung, was die Leistung verbessert und die Kosten senkt.
Redundanz und Zuverlässigkeit: Durch die Verteilung der Microservices auf Kubernetes über mehrere Rechenknoten wird automatisch eine höhere Redundanz erreicht. Wenn einer der Knoten ausfällt, kann Kubernetes die Microservices automatisch auf anderen funktionierenden Knoten verschieben, um sicherzustellen, dass die Anwendung ohne Unterbrechungen weiterläuft. Darüber hinaus bietet Kubernetes erweiterte Funktionen für die Überwachung und Verwaltung von Ressourcen, die dazu beitragen, ein hohes Maß an Zuverlässigkeit und Verfügbarkeit der Anwendung zu gewährleisten.
Architektur (lokal)¶
Der Cluster wurde mit Minikube erstellt. Minikube ist eine einfaches Mittel, um Kubernetes in einer lokalen Umgebung zu testen. Minikube erleichtert den Prozess der Bereitstellung eines Kubernetes-Clusters auf einer einzelnen Maschine und bietet eine Entwicklungserfahrung, die der in einer Cloud-Umgebung ähnelt. Minikube lässt dazu in einem Docker Container Kubernetes laufen. (Docker in Docker)
Deployment befindet sich unter dem Verzeichnis
./2_Kube/deployment. Darin befinden sich also die Konfigurationsdateien für das Deployment und Services. Die Deployment Datei definiert die Kubernetes-Ressourcen, die erforderlich sind, um das Deployment zu erstellen und zu verwalten. Das Deployment stellt sicher, dass die Anwendung “delivery-service” mit den erforderlichen Eigenschaften und Anzahl von Replikaten auf dem Kubernetes-Cluster bereitgestellt wird.
Am Beispiel des “delivery-service” erstellt die Deployment yaml eine bestimmte Anzahl von Replikate den Pod. Jeder Pod enthält einen Container, der das Docker-Image “delivery_service:latest” verwendet. Dieses Image wird verwendet, um die Anwendung innerhalb des Pods auszuführen. Der Container innerhalb des Pods öffnet den Port 3000, um den Verkehr zu empfangen und zu verarbeiten. Wenn ein Pod ausfällt oder gelöscht wird, startet das Deployment automatisch neue Pods, um sicherzustellen, dass die Anwendung weiterhin verfügbar ist.
Die Yaml Datei für “delivery-service” spezifiziert, dass der Service den Verkehr an Pods mit dem Label “app: delivery-service” weiterleiten soll. Darüber hinaus definiert es auch, an welchen Port der Service gebunden ist und an welchen Port die Pods, auf die der Service verweist, gebunden sind.
Wenn in Kubernetes eine Anfrage an http://delivery-service:3000 gestellt wird
sorgt das Control Plane dafür, dass die Request auf einen verfügbares Replikat
weitergeleitet wird damit kann einfach hohe Verfügbarkeit realisiert werden.
Bau der Services
Ein Client sendet eine POST-Anfrage an die API: Der Datenfluss beginnt, wenn ein Client eine POST-Anfrage an die API-Endpunkte im Kubernetes-Cluster sendet. Diese Anfrage enthält wahrscheinlich persönliche Daten oder andere Informationen, die verarbeitet werden sollen.
Der Master-Knoten des Clusters empfängt die Anfrage: Der Master-Knoten ist das zentrale Steuerelement des Kubernetes-Clusters. Er empfängt die eingehende POST-Anfrage, die vom Client gesendet wurde.
Der Master-Knoten leitet die Anfrage an den Service “Order” weiter: Basierend auf der Konfiguration und der Anforderung des Clusters leitet der Master-Knoten die eingehende Anfrage an den entsprechenden Service namens “Order” weiter. Dies kann durch den Einsatz von Kubernetes-Routen oder Load-Balancing-Mechanismen erfolgen, die sicherstellen, dass die Anfrage an den richtigen Service weitergeleitet wird.
Der Service “Order” verarbeitet die Anfrage und leitet sie gegebenenfalls an andere Services weiter: Der Service “Order” empfängt die Anfrage und führt die entsprechenden Aktionen aus, basierend auf den Anforderungen des Tasks. Dies kann das Weiterleiten der Anfrage an andere Services im Cluster umfassen, die für die Erledigung des Tasks erforderlich sind. Jeder dieser Services könnte spezifische Aufgaben ausführen, wie Datenvalidierung, Authentifizierung, Datenbankzugriff usw.
Die anderen Services führen ihre Aufgaben aus und geben eine Antwort zurück: Die weitergeleiteten Anfragen werden von den entsprechenden Services bearbeitet, die ihre spezifischen Aufgaben ausführen. Jeder Service verarbeitet die Anfrage und gibt gegebenenfalls eine Antwort zurück an den Service “Order”, der die Reaktion schließlich an den ursprünglichen Client zurückgibt.
Dieser Prozess zeigt, wie eine eingehende POST-Anfrage in einem Kubernetes-Cluster verarbeitet wird, wobei verschiedene Services im Cluster zusammenarbeiten, um die erforderlichen Aufgaben auszuführen und eine Antwort zurückzugeben.
Versuch¶
Im Versuch wollte wir ein einfache Beispielapplikation bauen, die uns die Konzepte von Kubernetes näher bringen.
Konzeption¶
Um eine Microservices-Architektur zu realisieren, war es zunächst erforderlich, ein Konzept zu entwickeln. Wir haben uns darauf konzentriert, eine einfache Modellierung einer Pizzeria zu erstellen. Dabei mussten die Abläufe und der grobe Datenaustausch festgelegt werden.
Als Ergebnis dieses Prozesses haben wir das folgende Sequenzdiagramm erstellt:
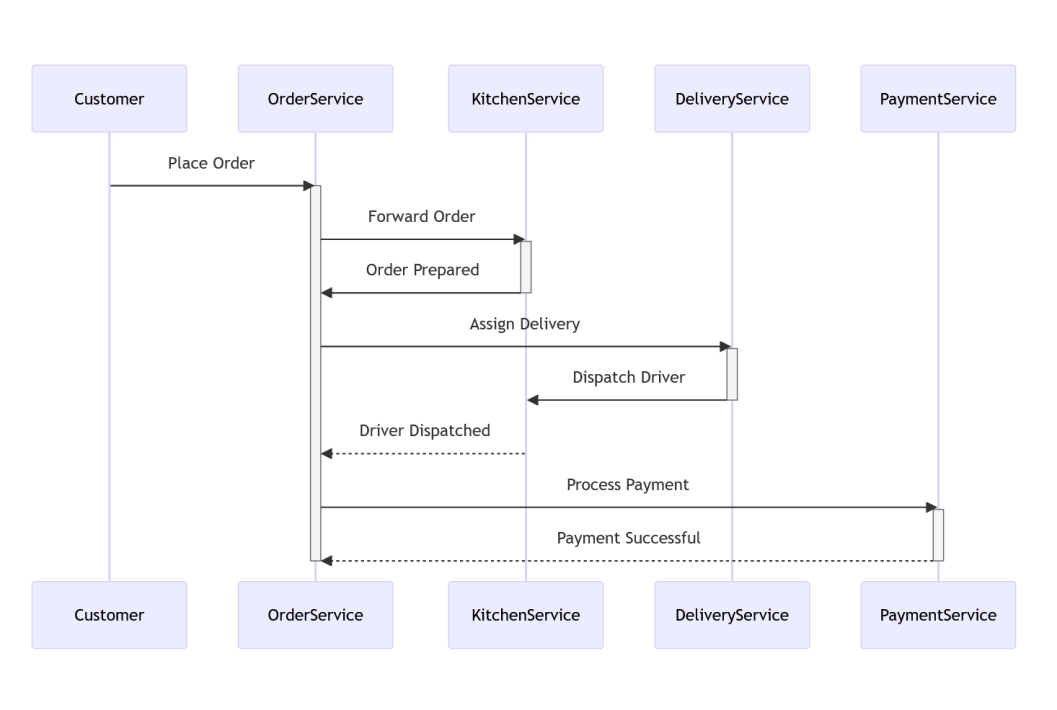
Basierend darauf mussten die einzelnen Schnittstellen definiert und implementiert werden.
Der Vorteil von Microservices liegt darin, dass die Implementierung unabhängig voneinander erfolgen kann. Jedes Team kann sich auf seinen eigenen Service konzentrieren, ohne auf andere Teams angewiesen zu sein. Dies ermöglicht es, die Stärken jedes Teams besser zu nutzen, da sie mit den Werkzeugen arbeiten können, die ihnen vertraut sind. Um dies zu demonstrieren, haben wir alle Services in verschiedenen Programmiersprachen implementiert.
Order (Rust)¶
Der Order-Service fungiert als Schnittstelle zur Außenwelt. Er leitet Kundenanfragen an die einzelnen Services weiter und bietet eine REST-API an. Der Service ist in Rust mit dem Tokio Web-Framework Axum implementiert.
Grundlegend bietet der Service die Route /create-order, um Bestellungen
entgegenzunehmen und sie dann an die Küche, den Delivery-Service und schließlich
die Bezahlung weiterzuleiten.
Darüber hinaus könnten die Services Statusupdates an /update-status senden,
was jedoch für diesen Versuch nicht implementiert wurde.
Kitchen (Java)¶
Der Kitchen-Service ist ein einfacher Webserver, welches in Java geschrieben
wurde. Als Framework bzw. Build Tool wurde Spring Boot und Gradle verwendet.
Die konkrete Implementierung des Servers kann unter dem Verzeichnis
./2_Kube/kitchen_service/src eingesehen werden. Im Grunde bietet der Server
zwei Endpunkte, an denen POST-Requests gesendet werden können.
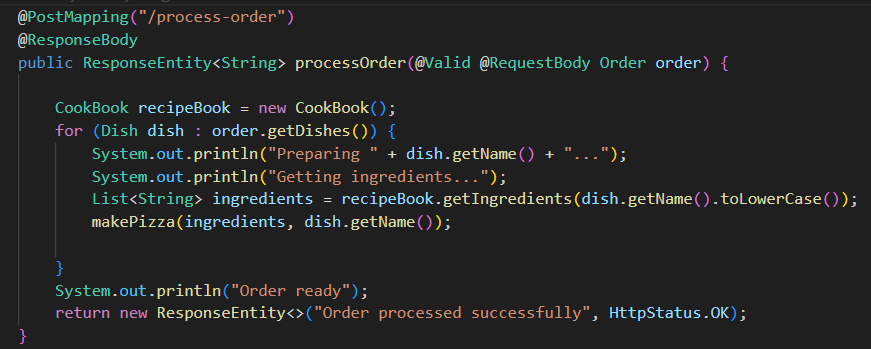
Bearbeitung von Bestellungen: Unter der Route
/process-orderwerden POST-Requests entgegengenommen, die Order-Objekte enthalten. Diese Objekte umfassen eine Liste der bestellten Gerichte, die Adresse des Bestellers und die Bestell-ID. Die Bestellung wird erst verarbeitet, wenn ein gültiges Objekt übergeben wurde. Der Server simuliert die Zubereitung der Gerichte, indem er die Zutaten heraussucht und die Pizzen fertigstellt. Sobald alle Gerichte fertig sind, wird eine Nachricht an den Order-Service gesendet, dass die Bestellung fertig und zur Lieferung bereit ist.
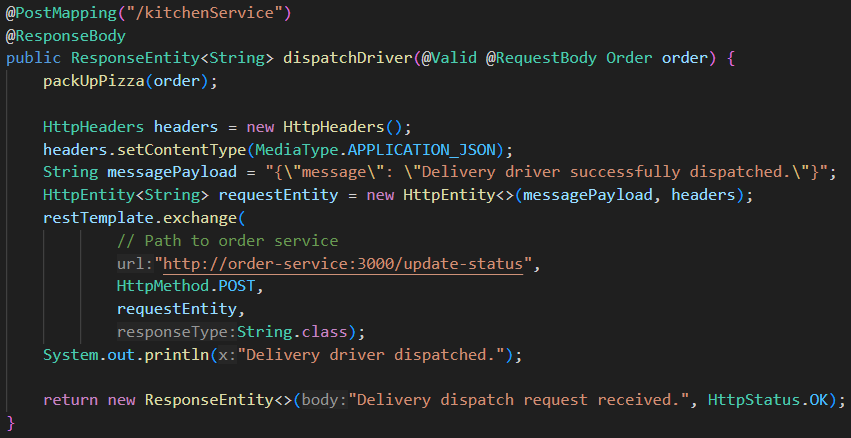
Übergabe der fertigen Bestellung an den Lieferdienst: Der Server erwartet unter der Route
/kitchenServiceeine Nachricht vom Delivery-Service, die ein Order-Objekt enthält. Wenn das Objekt gültig ist, werden die Gerichte für die Lieferung verpackt. Anschließend wird ein neuer POST-Request an den Order-Service weitergeleitet, mit der Mitteilung, dass die Bestellung erfolgreich an den Lieferdienst übergeben wurde. Zuletzt wird eine Bestätigungsnachricht an den Delivery-Service geschickt, um den Erhalt der Anfrage zu bestätigen.`
Payment (Javascript)¶
Dieser Service implementiert eine RESTful-API, die Transaktionsanfragen entgegennimmt und diese dann an den zugehörigen Bankdienst weiterleitet, basierend auf der IBAN des Kunden.
Transaktionsanfragen entgegennehmen: Der Server lauscht auf dem Endpunkt /process-transaction für POST-Anfragen. Diese Anfragen enthalten normalerweise Informationen über die Transaktion, wie die IBAN des Kunden und den Transaktionsbetrag.
Ermittlung des zugehörigen Bankdienstes: Nachdem der Server eine Transaktionsanfrage erhalten hat, verwendet er die IBAN des Kunden, um den zugehörigen BIC (Bank Identifier Code) der Kundenbank zu ermitteln. Dies geschieht durch Nachschlagen der IBAN in einem vordefinierten Dictionary (customerIBANs), das die Zuordnung von IBANs zu BICs enthält. Weiterleitung der Anfrage an die entsprechende Bank: Nachdem der BIC der Kundenbank ermittelt wurde, verwendet der Server diesen, um die zugehörige Bank-URL zu finden. Dies geschieht durch Nachschlagen des BIC in einem weiteren vordefinierten Dictionary (bankUrls), das die Zuordnung von BICs zu den URLs der Bank-APIs enthält. Die Transaktionsanfrage wird dann an diese Bank-URL weitergeleitet. Durchführung der Transaktion durch die Bank: Die Bank-API, die die Transaktionsanfrage erhält, ist für die Durchführung der Transaktion verantwortlich. Dies könnte das Überprüfen des Kontostands, die Überweisung von Geldern und andere Bankoperationen umfassen.
Delivery (Typescript)¶
Dieser Service ist ein einfacher Express-Server, der als RESTful API fungiert und bereits zubereitete Bestellungen für die Lieferung entgegennimmt, validiert, speichert und an einen anderen Service weiterleitet, der sich um die Küchenaktivitäten kümmert.
Entgegennahme von Bestellungen: Der Service nimmt fertig zubereitete Bestellungen vom OrderService entgegen Der Service hat einen einzigen Endpunkt definiert, der HTTP-POST-Anfragen unter
/deliveryServiceakzeptiert.Validierung von Bestellungen: Nachdem eine Bestellung eingegangen ist, validiert der Service die Bestelldaten gemäß dem definierten
orderSchema. Wenn die Daten gültig sind, wird die Bestellung unter Verwendung einer Kombination aus “D-” und der Bestellnummer als Schlüssel gespeichertZuweisen eines Fahrers: Nach erfolgreicher Validierung weist der Service der Bestellung einen Fahrer zu. Diese Zuweisung könnte Teil eines größeren Systems sein, das Fahrerdaten verwaltet und Verfügbarkeit überprüft.
Benachrichtigung der Küche: Sobald die Bestellung einem Fahrer zugewiesen wurde, sendet der Service eine Nachricht an die Küche, um sie darüber zu informieren, dass die Bestellung ausgeliefert werden kann. Dies geschieht über eine HTTP-POST-Anfrage mit den Bestelldaten an einen Endpunkt des Küchenservices.
Fehlerbehandlung und Rückmeldung an den Benutzer: Bei Fehlern während des Prozesses, wie zum Beispiel Problemen bei der Zuweisung eines Fahrers oder bei der Kommunikation mit dem Küchenservice, kann der Service entsprechende Fehlermeldungen an den Benutzer zurücksenden, um ihn über das Problem zu informieren.
Vorteile und Nachteile von Kubernetes¶
Vorteile:
Aufteilung von Verantvortlichkeiten
Unabhängige Komponenten
Ausfallsicherheit
Einfache und automatische Skalierbarkeit
Nachteile:
Viel Basiswissen erforderlich
Schwierig zu erlernen
Kubernetes im Vergleich zu Docker-compose¶
mehr Orchestrierungsfunktionalitäten
Management Computerübergreifend möglich
Pod Architektur: mehrere Container pro Pod möglich
Automatische Skalierung: Pods nach bedarf hoch- und runterfahren
Selbstheilung: Container automatisch neustarten bei Fehler
Quellen¶
https://kubernetes.io/docs/tutorials/kubernetes-basics/ aufgerufen: 11.04.2024
https://microservices.io/ aufgerufen: 11.04.2024
https://en.wikipedia.org/wiki/Microservices aufgerufen: 11.04.2024
https://bluelight.co/blog/docker-compose-vs-kubernetes aufgerufen: 13.04.2024