
Speicherlayout
Ein Computerprogramm besteht im Kern aus zwei Dingen: Aus Logik (Code) und Daten (Zustand). Während die Logik beschreibt, was getan werden soll, brauchen die Daten einen physischen Ort, an dem sie gespeichert werden.
Dieser physische Ort ist der Arbeitsspeicher (RAM). Der RAM ist wie ein gigantisches, fortlaufendes Band aus einzelnen Zellen (Bytes). Jede dieser Zellen hat eine eindeutige Nummer, eine Adresse.

Diese physische Realität ist in Hochsprachen meist vollständig abstrahiert. In der Systemprogrammierung jedoch ist das Verständnis, wo genau ein Byte liegt, essenziell für Performance und Korrektheit.
Diese Adressen sind in modernen Computern meistens 64-Bit1 lang und sehen
dann in etwa so aus 0x7ffee5cc7167. Da die meisten Daten nicht nur aus einem
Byte bestehen, werden diese einfach aufeinanderfolgend gespeichert.
Folgendes Beispiel soll dies verdeutlichen:
int main() { int a = 50;
return EXIT_SUCCESS;}Die Variable a ist vom Typ int. Dieser ist standardmäßig 4 Byte groß, hat
also vier aufeinanderfolgende Adressen. Das Speicherlayout der Variable sieht
dann so aus:

Die Anatomie eines Programms
Abschnitt betitelt „Die Anatomie eines Programms“Würden wir Daten und Code einfach wild in diesen riesigen Adressraum werfen, wäre Chaos die Folge. Code würde Daten überschreiben und Daten würden als Befehle interpretiert werden. Deshalb organisiert das Betriebssystem den Speicher jedes laufenden Programms in einer festen Struktur.

Hier befinden sich der Programmcode selbst (die Maschinenbefehle) und globale Daten, die von Anfang bis Ende existieren, z. B. String-Literale (“Hallo Welt”) oder globale static Variablen.
Die Größe dieses Bereichs steht schon fest, bevor das Programm überhaupt startet (zur Kompilierzeit).
Der Stack ist der Bereich für die unmittelbare Ausführung. Man kann ihn sich wie einen Stapel Teller vorstellen. Wenn eine Funktion aufgerufen wird, kommen ihre Daten auf den Stack. Wenn die Funktion endet, wird der Bereich automatisch freigegeben (der Teller wird abgeräumt).
 Bild generiert mit Google Nano Banana
Bild generiert mit Google Nano Banana
Wird eine Funktion aufgerufen, legt sie ihre lokalen Variablen oben auf den Stapel (“Push”). Kehrt die Funktion zurück, werden diese Daten sofort wieder verworfen (“Pop”).
Da die CPU lediglich einen Zeiger (den Stack Pointer) verschieben muss, ist die Speicherverwaltung hier extrem schnell, da kein freier Platz gesucht werden muss.
Aus den Coding Regeln der NASA “The Power of 10: Rules for Developing Safety-Critical Code”.2
Do not use dynamic memory allocation after initialization.
Der Heap ist das genaue Gegenteil des Stacks: Er ist ein riesiger, unstrukturierter Speicherbereich, vergleichbar mit einem chaotischen Parkplatz.
Hier können Daten beliebiger Größe abgelegt werden und so lange überleben, wie wir es wünschen, auch über Funktionsaufrufe hinaus.
Um hier Speicher zu bekommen, muss ein Allocator erst einen freien Platz suchen. Das kostet Zeit. Zudem muss das Programm sich merken, wo genau die Daten liegen (Pointer).
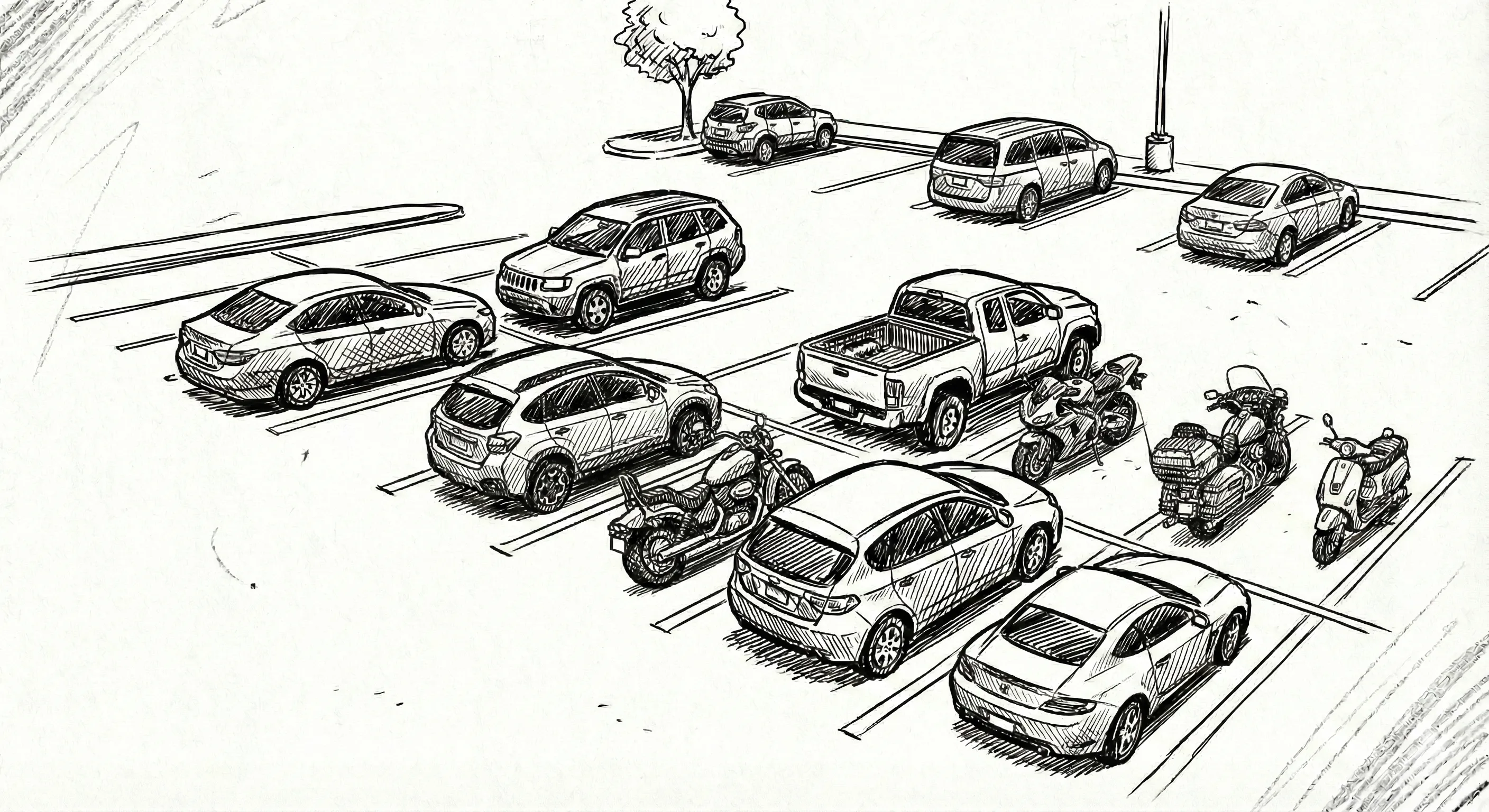 Bild generiert mit Google Nano Banana
Bild generiert mit Google Nano Banana
Rust Explizitheit vs. Abstraktion
Abschnitt betitelt „Rust Explizitheit vs. Abstraktion“In vielen Programmiersprachen wird dieses Layout vor dem Entwickler versteckt. In Python oder Java landet fast alles “irgendwo” auf dem Heap. Ein Garbage Collector (GC) räumt im Hintergrund auf. Das ist bequem, kostet aber Performance und führt zu unvorhersehbaren Pausen im Programmablauf. C hingegen überlässt dem Programmierer die volle manuelle Kontrolle, was oft zu Speicherlecks oder Sicherheitslücken führt.
Rust wählt einen anderen Weg: Es macht das Speicherlayout zum Teil des Typsystems. Anstatt zu raten, wo eine Variable liegt, diktiert der Typ ihren Ort. Rust zwingt uns, eine bewusste Entscheidung zwischen Stack und Heap zu treffen.
Standardmäßig landen Variablen in Rust auf dem Stack.
fn main() { //feste Größe (4 Bytes) -> Stack let a: i32 = 50;}Will man Daten auf den Heap legen, muss man dies explizit tun.
Ein Typ wie Box<T> ist eigentlich ein Pointer, der auf dem Stack liegt, aber
auf Daten im Heap zeigt.
fn main() { // b (Pointer) -> Stack (64bit) // 50 (Daten) -> Heap let b = Box::new(50);}https://www.reddit.com/r/rust/comments/1f59yz3/what_does_memorysafe_actually_mean/
https://github.com/Speykious/cve-rs
Footnotes
Abschnitt betitelt „Footnotes“-
Bei einer 32-Bit-Architektur hat der Computer für die Adressen nur 32 Stellen Platz. Die maximale Anzahl an Kombinationen ist 2^32. Das ergibt exakt 4.294.967.296 mögliche Adressen. Da jede Adresse genau auf 1 Byte zeigt, ist bei ca. 4 Gigabyte Schluss. Selbst wenn 16 GB RAM in einem Computer stecken, kann der Prozessor die Speicherzellen oberhalb der 4 GB nicht ansprechen, weil ihm schlicht die Zahlen ausgehen, um sie zu benennen. Mit 64-Bit stehen 18 Trillionen Adressen zur Verfügung (16 Exabyte). Das ist genug, um jedem Sandkorn auf der Erde eine eigene Speicheradresse zu geben. ↩
-
https://en.wikipedia.org/wiki/The_Power_of_10:_Rules_for_Developing_Safety-Critical_Code ↩