Echtzeitsysteme¶
Einleitung¶
Die Planung und Verwaltung von Aufgaben in Echtzeitsystemen (Real-Time Operating Systems, RTOS) ist ein komplexes und kritisches Thema in der Informatik. Echtzeitsysteme zeichnen sich dadurch aus, dass sie Aufgaben innerhalb strikter zeitlicher Vorgaben, sogenannter Deadlines, ausführen müssen. Diese Systeme finden Anwendung in sicherheitskritischen Bereichen wie der Luft- und Raumfahrt, der Automobilsteuerung und der industriellen Automatisierung, wo das Versagen bei der Einhaltung von Deadlines schwerwiegende Konsequenzen haben kann.
Ein zentraler Bestandteil von RTOS ist das Scheduling, also die zeitliche Planung und Zuweisung von Prozessorressourcen an verschiedene Aufgaben. Ein Prozessorkern kann gleichzeitig nur eine Aufgabe zu jedem gegebenen Zeitpunkt bearbeiten. Bei mehreren Aufgaben muss er zwischen Aufgaben wechseln, wenn eine quasiparallele Bearbeitung gewünscht ist. Diese Fähigkeit, effizient zwischen Aufgaben zu wechseln, ist entscheidend für die Leistung und Zuverlässigkeit eines Echtzeitsystems.
In Echtzeitsystemen ist es von entscheidender Bedeutung, dass Tasks (Aufgaben) innerhalb ihrer vorgegebenen Deadlines ausgeführt werden. Dies ist besonders wichtig in sicherheitskritischen Anwendungen wie der Luft- und Raumfahrt, der Automobilsteuerung und der industriellen Automatisierung. Die Einhaltung dieser Deadlines ist essenziell, um die Sicherheit und Funktionalität der Systeme zu gewährleisten.
Es gibt verschiedene Algorithmen zur Durchführung des Schedulings in RTOS, darunter Fixed-Priority Scheduling, Earliest Deadline First (EDF) und Least Laxity First (LLF). Jeder dieser Algorithmen hat spezifische Vor- und Nachteile, die in Abhängigkeit von den jeweiligen Systemanforderungen und -bedingungen abzuwägen sind. Fixed-Priority Scheduling zeichnet sich durch seine Einfachheit und Vorhersagbarkeit aus, kann jedoch unter bestimmten Umständen zu Prioritätsinversion führen. Dynamische Algorithmen wie EDF und LLF bieten theoretisch eine bessere Ressourcennutzung und Flexibilität, haben sich aber in der Praxis nicht immer als zuverlässig in Bezug auf die Einhaltung von Deadlines erwiesen.
Die Wahl des richtigen Scheduling-Algorithmus ist somit eine kritische Entscheidung bei der Entwicklung von RTOS, die eine sorgfältige Analyse der spezifischen Systemanforderungen erfordert. Es gibt keine universelle Lösung; vielmehr muss ein maßgeschneiderter Ansatz entwickelt werden, der den individuellen zeitlichen Anforderungen und Ressourcenbeschränkungen des Systems gerecht wird.
Inverse Pendol¶
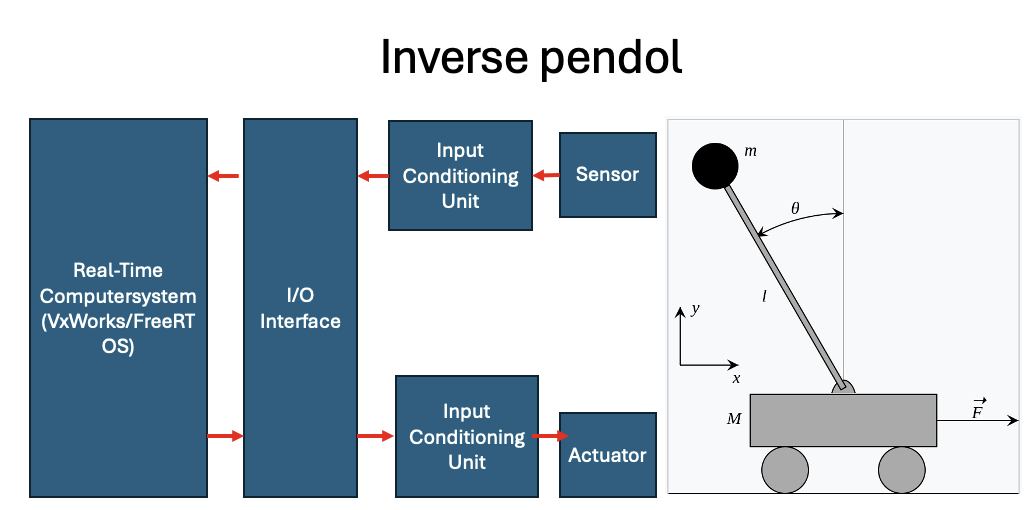
Das Problem des inversen Pendels ist ein klassisches Beispiel für ein Echtzeitsystem (RTOS), das verwendet wird, um Konzepte der Stabilität, Steuerung und Planung zu veranschaulichen. Das inverse Pendel besteht aus einer Stange mit einer Masse am Ende, die auf einem Wagen montiert ist, der sich horizontal bewegen kann. Das Ziel ist es, das Pendel trotz äußerer Störungen in einer aufrechten Position zu halten, indem die Bewegung des Wagens gesteuert wird.
Beschreibung des Systems¶
Echtzeit-Betriebssystem (RTOS): Wird verwendet, um die Steuerungsoperationen in Echtzeit auszuführen. Gängige Beispiele sind VxWorks und FreeRTOS.
I/O-Schnittstelle: Sorgt für die Kommunikation zwischen dem Steuerungssystem und den Hardwarekomponenten wie Sensoren und Aktoren.
Sensor: Misst den Winkel des Pendels und die Position des Wagens.
Eingangsaufbereitungseinheit: Bereitet die Signale des Sensors auf, um sie dem Echtzeitsystem zur Verfügung zu stellen.
Aktuator: Bewegt den Wagen basierend auf den Steuerbefehlen des Echtzeitsystems.
Eingangsaufbereitungseinheit: Bereitet die Steuerbefehle des Echtzeitsystems auf und leitet sie an den Aktuator weiter.
Mögliche Probleme in Echtzeitsystemen¶
Zeitliche Verzögerungen: Jede Verzögerung in der Signalverarbeitung kann dazu führen, dass das Pendel instabil wird. Das Echtzeitsystem muss in der Lage sein, innerhalb strikter Zeitvorgaben zu arbeiten.
Prioritätsinversion: Ein niedriger priorisierter Task blockiert einen höher priorisierten Task, was zu Verzögerungen führen kann.
Überlastung des Prozessors: Wenn zu viele Tasks gleichzeitig ausgeführt werden müssen, kann der Prozessor überlastet werden, was zu verpassten Deadlines führen kann.
Sensor- und Aktuatorausfälle: Fehlerhafte Sensoren oder Aktuatoren können falsche Daten liefern oder die Steuerung beeinträchtigen.
Kontextwechsel: Häufige Kontextwechsel können zu einer erhöhten Systemlatenz führen, was die Reaktionszeit des Steuerungssystems beeinträchtigt.
Ungenaue Zeitplanung: Falsche Schätzungen der benötigten Zeit für die Ausführung von Tasks können dazu führen, dass Deadlines verpasst werden.
Hard Real-Time Anforderungen¶
Determinismus:
Alle Operationen werden vorhersagbar und konsistent ausgeführt.
Das System produziert dieselbe Reaktion bei gleichen Eingabebedingungen.
Sofortige Reaktion:
Das System muss sofort auf Eingangssignale oder externe Ereignisse reagieren.
Datenverarbeitung und Steuerbefehlsgenerierung erfolgen innerhalb eines sehr kurzen und vorher festgelegten Zeitintervalls.
Interrupt-Handling:
Unterbrechungen oder Ereignisse, die sofortige Reaktionen erfordern, werden effizient und vorhersagbar verwaltet.
Priorisierte Steuerbefehle werden ohne Verzögerung verarbeitet.
Zeitliche Analyse und Latenzen in Echtzeitsystemen¶
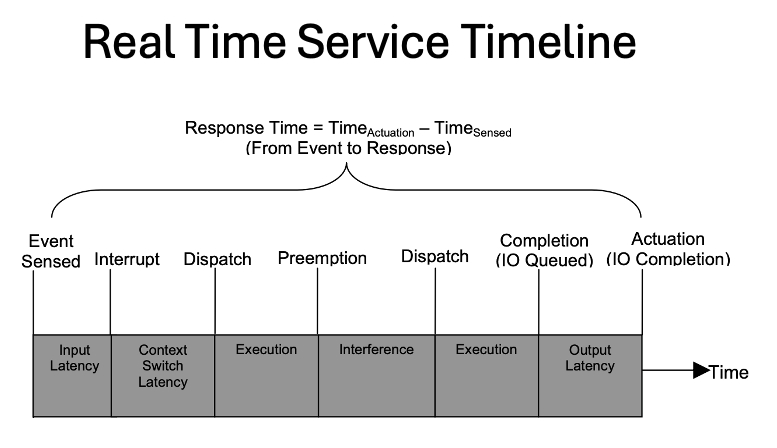
Die Abbildung zeigt eine “Real Time Service Timeline”, die den Zeitverlauf eines Echtzeitdienstes von der Ereigniserfassung bis zur Aktuierung darstellt. Die Zeitleiste ist in mehrere Phasen unterteilt, die verschiedene Verzögerungen und Prozesse innerhalb eines Echtzeitsystems beschreiben.
Phasen und Verzögerungen:¶
Event Sensed (Ereigniserfassung):
Input Latency (Eingangsverzögerung): Dies ist die Verzögerung, die auftritt, wenn ein Ereignis erkannt wird, bevor das System auf dieses Ereignis reagieren kann.
Interrupt (Unterbrechung):
Context Switch Latency (Kontextwechsel-Latenz): Diese Verzögerung tritt auf, wenn das System einen Kontextwechsel durchführt, um auf das Ereignis zu reagieren. Ein Kontextwechsel ist erforderlich, um von der aktuellen Aufgabe zu der Aufgabe zu wechseln, die das Ereignis verarbeitet.
Dispatch (Bereitstellung):
Execution (Ausführung): In dieser Phase führt das System die notwendigen Schritte zur Ereignisverarbeitung aus.
Preemption (Unterbrechung):
Interference (Interferenz): Diese Phase beschreibt die potenziellen Unterbrechungen oder Interferenzen, die auftreten können, während das System andere Aufgaben ausführt.
Dispatch (Bereitstellung):
Execution (Ausführung): Diese Phase wiederholt die Ausführungsphase, um die Aufgabe fortzusetzen, nachdem die Interferenzen behoben wurden.
Completion (Abschluss) (IO Queued):
Output Latency (Ausgangsverzögerung): Dies ist die Verzögerung, die auftritt, wenn das Ergebnis der Ereignisverarbeitung in eine Warteschlange gestellt wird, bevor die eigentliche Aktion ausgeführt wird.
Actuation (Aktuierung) (IO Completion):
Diese Phase markiert den Abschluss der Aktuierung und die Ausführung der entsprechenden Aktion basierend auf dem erfassten Ereignis.
Gesamtlatenz und Antwortzeit:¶
Response Time (Antwortzeit): Dies ist die Gesamtzeit vom Erkennen des Ereignisses (Time({Sensed})) bis zur Ausführung der entsprechenden Aktion (Time({Actuation})). Die Antwortzeit wird durch die Formel berechnet: [ \text{Response Time} = \text{Time}{\text{Actuation}} - \text{Time}{\text{Sensed}} ]
Die Abbildung verdeutlicht die verschiedenen Verzögerungen und Phasen, die in einem Echtzeitsystem berücksichtigt werden müssen, um sicherzustellen, dass die Systemreaktion innerhalb der erforderlichen Zeitgrenzen bleibt. Dies ist besonders wichtig in sicherheitskritischen Anwendungen, bei denen verzögerte Reaktionen schwerwiegende Konsequenzen haben können.
Arten von Echtzeitsystemen:¶
General Purpose Betriebssysteme (Linux, Windows, Android):
Priorität ist die user experience.
Echtzeitbetriebssysteme (FreeRTOS):
Priorität ist die Einhaltung von Aufgaben-deadlines.
Bare Metal (Super Loop, ohne Betriebssystem):
Kein Scheduling, jede Aufgabe hat eine vordefinierte Zeitscheibe. Ideal, wenn es nur wenige Aufgaben gibt.
Um Deadlines bestmöglich einhalten zu können, bedarf es an Algorithmen, welche die Aufgaben anhand deren Perioden, Ausführungszeiten und Deadlines in eine optimale Reihenfolge sortiert.
In diesem Experiment haben wir unterschiedliche Algorithmen verwendet, um die Ausführung einer Menge von Tasks zu simulieren und zu überprüfen, ob diese innerhalb ihrer Deadlines abgeschlossen werden können.
Untersuchte Algorithmen¶
Rate Monotonic Scheduling
Deadline Monotonic Scheduling
Least Laxity First Scheduling
Earliest Deadline First Scheduling
Versuch¶
Rate Monotonic Scheduling (RMS)¶
Rate-Monotonic Scheduling (RMS) ist ein Algorithmus für das Scheduling von periodischen Aufgaben in Echtzeitsystemen. RMS ordnet den Aufgaben Prioritäten basierend auf ihren Perioden zu und führt eine präemptive Ausführung der Aufgaben durch, wobei die Aufgabe mit der höchsten Priorität zu einem gegebenen Zeitpunkt ausgeführt wird. Wenn eine Aufgabe beendet ist oder blockiert wird, wird die nächste Aufgabe mit der höchsten Priorität ausgeführt. Dieser Zyklus setzt sich fort, bis alle Aufgaben abgeschlossen sind oder bis der Zeitrahmen des Systems abgelaufen ist.
Voraussetzungen¶
Periodische Aufgaben: RMS ist für Systeme geeignet, in denen die Aufgaben periodisch auftreten. Jede Aufgabe hat eine feste Periode, in der sie regelmäßig ausgeführt werden muss.
Deterministische Ausführungszeiten: Die Ausführungszeiten der Aufgaben müssen deterministisch sein, d.h., sie müssen vorhersehbar und konstant sein. RMS setzt voraus, dass die Ausführungszeiten der Aufgaben während ihres gesamten Lebenszyklus gleich bleiben.
Präemptives Scheduling: RMS verwendet präemptives Scheduling, was bedeutet, dass eine laufende Aufgabe unterbrochen werden kann, um einer höher priorisierten Aufgabe die Ausführung zu ermöglichen. Dies erfordert eine Hardware- oder Betriebssystemunterstützung, die die präemptive Ausführung von Aufgaben ermöglicht.
Kurze relative Deadline: Jede Aufgabe hat eine relative Deadline, die der Periode der Aufgabe entspricht. Damit RMS korrekt funktioniert, sollten die relativen Deadlines kurz im Vergleich zur Periode sein. Andernfalls steigt das Risiko von Deadline-Verletzungen.
Die Task-Klasse repräsentiert eine Aufgabe mit Eigenschaften wie Name, Periode
und Ausführungszeit.
Task: Klasse zur Darstellung eines Tasks mit Name, Periode, Ausführungszeit, verbleibender Zeit und nächster Frist.
lcm und lcm_multiple: Funktionen zur Berechnung des kleinsten gemeinsamen Vielfachen (LCM) von zwei oder mehreren Zahlen. rate_monotonic_scheduling: Funktion zur Durchführung der Rate Monotonic Scheduling Simulation.
is_schedulable: Funktion zur Überprüfung, ob die Menge der Tasks planbar ist.
class Task:
def __init__(self, name, period, execution_time):
self.name = name
self.period = period
self.execution_time = execution_time
self.remaining_time = execution_time
self.next_deadline = period
def __lt__(self, other):
return self.period < other.period
Scheduling-Analyse¶
Eine wichtige Eigenschaft von RMS ist die analytische Bestimmung der Schedulbarkeit eines Task-Sets. Laut dem Liu-Layland-Kriterium ist ein Task-Set schedulbar, wenn die Gesamtauslastung ( U ) unter einem bestimmten Grenzwert liegt:
[ U = \sum_{i=1}^n \frac{C_i}{T_i} \leq n(2^{1/n} - 1) ]
Für große ( n ) konvergiert der Ausdruck ( n(2^{1/n} - 1) ) gegen etwa 0.693. Das bedeutet, dass die Gesamtauslastung eines Systems für eine beliebige Anzahl von Tasks nicht mehr als ca. 69.3% betragen sollte, um sicherzustellen, dass alle Deadlines eingehalten werden können.
Die Funktion is_schedulable(tasks) analysiert die Schedulbarkeit eines Task-Sets basierend auf dem Liu-Layland-Kriterium.
def is_schedulable(tasks):
n = len(tasks)
U = sum(task.execution_time / task.period for task in tasks)
U_bound = n * (2 ** (1 / n) - 1)
return U <= U_bound
Initialisierung und Schedulability Check:¶
Drei Tasks werden initialisiert.
Überprüft, ob die Menge der Tasks planbar ist, indem die Gesamtnutzungsrate mit der Grenznutzungsrate verglichen wird.
Simulation¶
Die Prioritätswarteschlange (heapq) wird verwendet, um die Tasks basierend auf ihrer Periode zu ordnen. Die Simulation läuft für die gesamte Simulationszeit (total_time), die als LCM der Perioden der Tasks berechnet wird. Es wird protokolliert, welcher Task zu welcher Zeit ausgeführt wird, und überprüft, ob eine Frist verpasst wird.
Implementierung¶
Die Funktion rate_monotonic_scheduling implementiert den RMS-Algorithmus,
indem sie eine Prioritätswarteschlange verwendet, um die Aufgaben nach ihren
Perioden zu ordnen. Die Aufgaben werden basierend auf ihrer Priorität präemptiv
ausgeführt, wobei Aufgaben mit kürzeren Perioden Vorrang haben.
def rate_monotonic_scheduling(tasks, total_time):
time = 0
task_queue = []
for task in tasks:
heapq.heappush(task_queue, task)
execution_log = []
while time < total_time:
if task_queue:
current_task = heapq.heappop(task_queue)
if current_task.remaining_time > 0:
execution_log.append((time, current_task.name))
current_task.remaining_time -= 1
time += 1
if current_task.remaining_time > 0:
heapq.heappush(task_queue, current_task)
else:
execution_log.append((time, "idle"))
time += 1
else:
execution_log.append((time, "idle"))
time += 1
for task in tasks:
if time % task.period == 0:
if task.remaining_time > 0:
print(f"Deadline missed for task {task.name} at time {time}")
return execution_log, False
if task not in task_queue:
task.remaining_time = task.execution_time
task.next_deadline += task.period
heapq.heappush(task_queue, task)
return execution_log, True
Beispiel¶
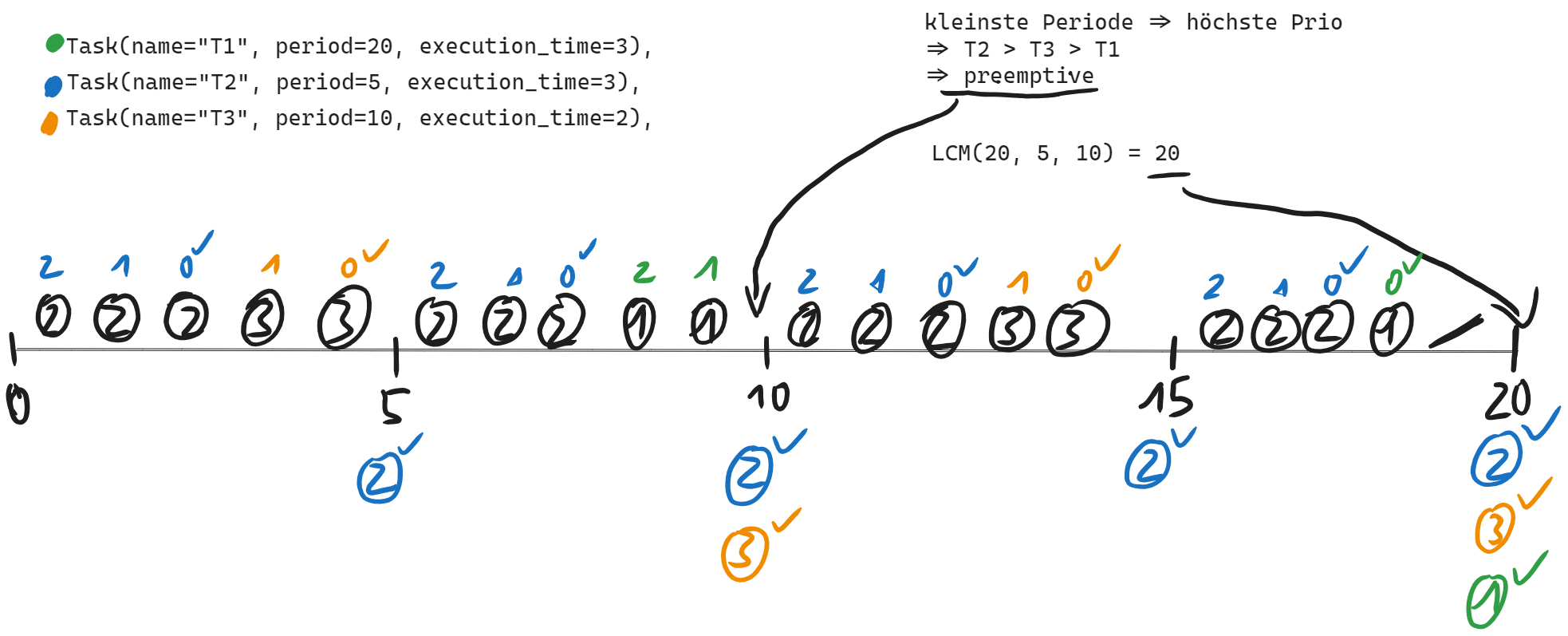
tasks = [
Task(name="T1", period=20, execution_time=3),
Task(name="T2", period=5, execution_time=3),
Task(name="T3", period=10, execution_time=2),
]
total_time = 20 # lcm(20, 5, 10) = 20
**might** not be schedulable
Time 0: T2
Time 1: T2
Time 2: T2
Time 3: T3
Time 4: T3
Time 5: T2
Time 6: T2
Time 7: T2
Time 8: T1
Time 9: T1
Time 10: T2
Time 11: T2
Time 12: T2
Time 13: T3
Time 14: T3
Time 15: T2
Time 16: T2
Time 17: T2
Time 18: T1
Time 19: idle
Scheduling was successful within total time.
Deadline Monotonic Scheduling¶
Deadline Monotonic Scheduling (DMS) ist ein prioritätsbasierter Scheduling-Algorithmus für periodische Echtzeittasks. Der Algorithmus weist jedem Task eine Priorität basierend auf seiner relativen Deadline zu: Tasks mit kürzeren Deadlines erhalten höhere Prioritäten. Im Gegensatz zu Rate Monotonic Scheduling (RMS), das die Prioritäten basierend auf den Perioden der Tasks zuweist, berücksichtigt DMS explizit die Deadlines, was in bestimmten Szenarien zu einer besseren Planbarkeit führen kann.
Ziel des Experiments¶
Das Ziel des Experiments war es zu demonstrieren, wie der DMS-Algorithmus verwendet werden kann, um eine Menge von periodischen Tasks so zu planen, dass alle Tasks ihre Deadlines einhalten. Dies beinhaltete:
Die Überprüfung der Planbarkeit (Schedulability) der Tasks unter Verwendung des DMS-Algorithmus. Die Simulation der Task-Ausführung über eine Periode, die das kleinste gemeinsame Vielfache (LCM) der Perioden der Tasks ist. Die Protokollierung der Ausführungszeiten der Tasks, um sicherzustellen, dass alle Deadlines eingehalten werden.
Durchführung des Experiments¶
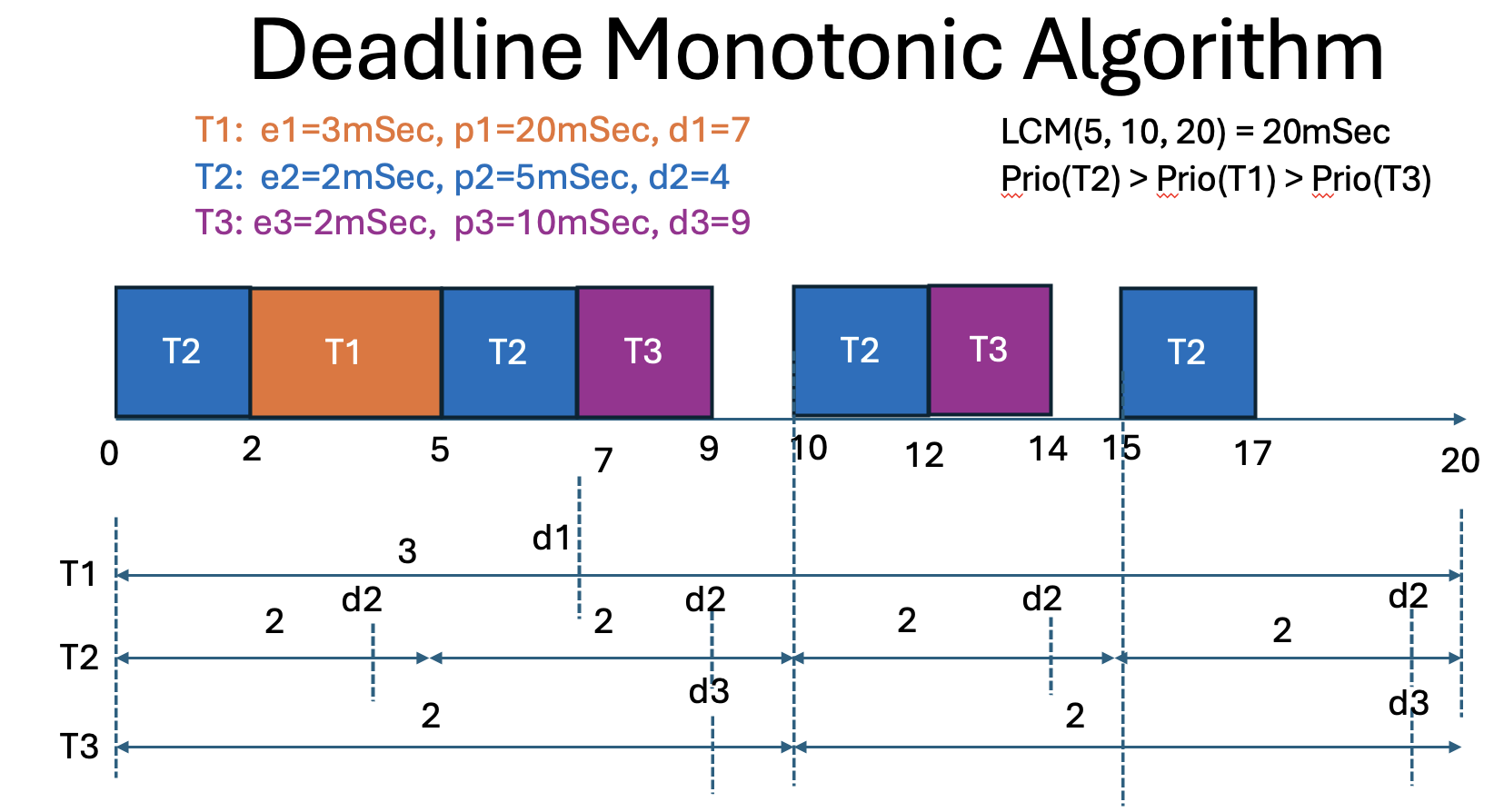
Definition der Tasks: Drei Tasks wurden definiert mit folgenden Parametern:
Task T1: Periode = 20 ms, Ausführungszeit = 3 ms, Deadline = 7 ms Task T2: Periode = 5 ms, Ausführungszeit = 2 ms, Deadline = 4 ms Task T3: Periode = 10 ms, Ausführungszeit = 2 ms, Deadline = 9 ms Schedulability Check: Bevor die eigentliche Simulation durchgeführt wurde, wurde überprüft, ob die Tasks planbar sind, indem der Nutzungsfaktor berechnet und mit einer Grenze verglichen wurde.
Simulation: Eine Prioritätswarteschlange wurde verwendet, um die Tasks basierend auf ihren Deadlines zu ordnen. Die Simulation wurde über eine Zeitdauer durchgeführt, die dem LCM der Perioden der Tasks entsprach. Während der Simulation wurden die folgenden Schritte ausgeführt:
Tasks wurden gemäß ihrer Priorität (Deadline) aus der Warteschlange entnommen und ausgeführt. Nach Abschluss der Ausführung eines Tasks oder beim Erreichen seiner Periode wurde der Task zurückgesetzt und erneut in die Warteschlange eingefügt.
Ergebnis¶
Die Simulation ergab, dass alle Tasks innerhalb ihrer jeweiligen Deadlines ausgeführt wurden und die Planung erfolgreich war:
**might** not be schedulable
Time 0: T2
Time 1: T2
Time 2: T1
Time 3: T1
Time 4: T1
Time 5: T2
Time 6: T2
Time 7: T3
Time 8: T3
Time 9: idle
Time 10: T2
Time 11: T2
Time 12: T3
Time 13: T3
Time 14: idle
Time 15: T2
Time 16: T2
Time 17: idle
Time 18: idle
Time 19: idle
Least-Laxity-First (LLF) Algorithmus¶
Der Least-Laxity-First (LLF) Algorithmus ist eine dynamische Scheduling-Methode, die in Echtzeitsystemen verwendet wird. Er priorisiert Aufgaben basierend auf ihrer Laxity, die den Unterschied zwischen der verbleibenden Zeit bis zur Deadline und der verbleibenden Rechenzeit darstellt.
Algorithmus-Beschreibung: Für jede Aufgabe, die zu einem gegebenen Zeitpunkt ausführbar ist, wird die Laxity 𝑆 als 𝑆 = 𝐷 − 𝐶 berechnet, wobei 𝐷 die verbleibende Zeit bis zur Deadline und 𝐶 die verbleibende Rechenzeit ist. Die Aufgabe mit der kleinsten Laxity wird als nächstes zur Ausführung ausgewählt.
Kontextwechsel: Wenn eine andere Aufgabe als die aktuell laufende die kleinste Laxity hat, erfolgt ein Kontextwechsel. Dynamische Anpassung: Dieser Prozess wird dynamisch bei jedem Scheduling-Punkt wiederholt, wobei die Prioritäten entsprechend dem Systemzustand angepasst werden.
Vorteile¶
Optimale Planung: LLF ist ein optimaler Scheduling-Algorithmus, was bedeutet, dass, wenn ein Satz von Aufgaben planbar ist, er durch LLF geplant werden kann.
Keine festen Prioritäten: Im Gegensatz zu festgelegten Prioritäten erfordert LLF keine vorab zugewiesenen Prioritätsstufen für Aufgaben. Dies reduziert die Komplexität der Prioritätszuweisung während der Entwicklungsphase.
Sofortige Erkennung von Deadline-Verstößen: LLF kann potenzielle Deadline-Verstöße in Echtzeit erkennen, da das Erreichen einer Laxity von null durch eine Aufgabe auf einen bevorstehenden Deadline-Verstoß hinweist. Dies ermöglicht rechtzeitige Eingriffe und Notfallmaßnahmen.
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣤⢔⣒⠂⣀⣀⣤⣄⣀ ⠀⠀⠀⠀⠀⠀⠀⣴⣿⠋⢠⣟⡼⣷⠼⣆⣼⢇⣿⣄⠱⣄ ⠀⠀⠀⠀⠀⠀⠀⠹⣿⡀⣆⠙⠢⠐⠉⠉⣴⣾⣽⢟⡰⠃ ⠀⠀⠀⠀⠀⠀⠀⠀⠈⢿⣿⣦⠀⠤⢴⣿⠿⢋⣴⡏ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⢸⡙⠻⣿⣶⣦⣭⣉⠁⣿ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣷⠀⠈⠉⠉⠉⠉⠇⡟ ⠀⠀⠀⠀⠀⠀⠀⢀⠀⠀⣘⣦⣀⠀⠀⣀⡴⠊ ⠀⠀⠀⠀⠀⠀⠀⠈⠙⠛⠛⢻⣿⣿⣿⣿⠻⣧⡀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠫⣿⠉⠻⣇⠘⠓⠂ ⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⣿ Sorry Deadline missed for task T1 at time 20
Nachteile¶
Hoher Rechenaufwand: LLF erfordert die Berechnung von Laxities und das ständige Überprüfen dieser Werte für alle ausführbaren Aufgaben, was zu einem erheblichen Rechenaufwand bei jedem Scheduling-Punkt führt.
Thrashing: In Szenarien, in denen mehrere Aufgaben die kleinste Laxity haben, kann LLF häufige Kontextwechsel zwischen diesen Aufgaben verursachen. Dieses Thrashing-Verhalten führt zu einer hohen Anzahl von Kontextwechseln, die zusätzlichen Rechenzeit- und Ressourcenverbrauch verursachen.
Komplexe Planbarkeitsanalyse: Die häufigen Kontextwechsel und die dynamische Natur des Algorithmus machen die Offline-Planbarkeitsanalyse komplizierter im Vergleich zu statischen Scheduling-Algorithmen.
Earliest deadline first (EDF)¶
Was ist der Earliest Deadline First Algorithmus und wie funktioniert er?¶
Der Earliest Deadline First (EDF) Algorithmus ist ein dynamischer Scheduling-Algorithmus, der hauptsächlich in Echtzeitsystemen verwendet wird. Bei EDF wird jede Aufgabe (Task) nach ihrer Deadline (Frist) priorisiert – das bedeutet, die Aufgabe mit der frühesten Deadline erhält die höchste Priorität und wird als nächstes ausgeführt.
Der Algorithmus funktioniert wie folgt:¶
Erstellung einer Task-Liste: Jede Aufgabe hat eine Ausführungszeit und eine Deadline.
Sortieren der Tasks: Die Aufgaben werden nach ihrer Deadline sortiert.
Ausführen der Tasks: Die Aufgabe mit der frühesten Deadline wird zuerst ausgeführt. Dieser Prozess wiederholt sich, bis alle Aufgaben erledigt sind oder bis eine Aufgabe die Frist nicht einhalten kann.
Wofür wird er verwendet?¶
Der EDF-Algorithmus wird hauptsächlich in Echtzeit-Betriebssystemen und eingebetteten Systemen verwendet, wo es entscheidend ist, dass Aufgaben innerhalb einer bestimmten Frist abgeschlossen werden. Beispiele dafür sind:
Automobilindustrie: Zur Steuerung von Airbags oder Antiblockiersystemen (ABS).
Medizinische Geräte: Zur Überwachung und Steuerung von lebenserhaltenden Systemen.
Telekommunikation: Zur Verwaltung von Netzwerkressourcen und Echtzeit-Datenübertragung.
Vorteile¶
Optimalität: Der EDF-Algorithmus ist optimal für eine einzelne Prozessorumgebung. Das bedeutet, wenn es irgendeine Möglichkeit gibt, alle Aufgaben rechtzeitig abzuschließen, wird EDF diese finden.
Einfachheit: Die Implementierung des Algorithmus ist relativ einfach, da er lediglich die Aufgaben nach ihrer Deadline sortieren muss.
Dynamische Priorität: Im Gegensatz zu festen Prioritätsalgorithmen kann EDF dynamisch auf Veränderungen in den Deadlines reagieren und die Aufgaben entsprechend neu priorisieren.
Nachteile¶
Hohe Berechnungskosten bei häufigen Updates: Da der Algorithmus die Aufgaben bei jeder Änderung der Task-Liste neu sortieren muss, kann dies zu hohen Berechnungskosten führen, insbesondere bei Systemen mit vielen Aufgaben.
Deadline-Miss: In Systemen mit hoher Auslastung besteht die Gefahr, dass Aufgaben ihre Deadlines verpassen, wenn die Summe der Ausführungszeiten die verfügbare Zeit überschreitet.
Nicht-Preemptiv: Standardmäßig ist EDF nicht preemptiv, was bedeutet, dass eine laufende Aufgabe nicht unterbrochen wird, auch wenn eine Aufgabe mit einer früheren Deadline ankommt. Dies kann in bestimmten Echtzeitsystemen problematisch sein.
Zusammenfassung¶
Der Earliest Deadline First (EDF) Algorithmus ist ein effizienter und weit verbreiteter Scheduling-Algorithmus für Echtzeitsysteme, der Aufgaben nach ihren Deadlines priorisiert. Während er viele Vorteile in Bezug auf Einfachheit und Optimalität bietet, kann er in stark ausgelasteten Systemen zu Herausforderungen führen. Dennoch bleibt EDF aufgrund seiner Effektivität und klaren Prioritätsregeln eine bevorzugte Wahl in vielen Echtzeitanwendungen.
Fazit¶
Das Thema Scheduling-Algorithmen für Echtzeitsysteme ist von entscheidender Bedeutung in der Informatik und insbesondere in der Entwicklung von Systemen, die in zeitkritischen Umgebungen operieren. Echtzeitsysteme erfordern präzise und verlässliche Methoden zur Verwaltung von Prozessen und Aufgaben, um sicherzustellen, dass sie innerhalb bestimmter Zeitrahmen abgeschlossen werden.
Es gibt verschiedene Algorithmen, die sich für das Scheduling in Echtzeitsystemen eignen, darunter Fixed-Priority Scheduling, Earliest Deadline First (EDF) und Least Laxity First (LLF). Jeder dieser Algorithmen hat seine eigenen Vor- und Nachteile, die je nach Anwendungsszenario abzuwägen sind.
Unsere Experimente haben gezeigt, dass Fixed-Priority Scheduling die Deadlines zuverlässig einhält, während dynamische Scheduling-Algorithmen dies nicht immer schaffen. Fixed-Priority Scheduling ist einfach zu implementieren und gut verstanden, aber es kann zu Problemen wie Prioritätsinversion führen, bei denen niedrig priorisierte Aufgaben höher priorisierte Aufgaben blockieren können. Trotzdem hat sich dieser Algorithmus in unseren Tests als zuverlässig erwiesen, wenn es darum geht, zeitkritische Aufgaben fristgerecht zu erledigen.
Im Gegensatz dazu bieten dynamische Scheduling-Algorithmen wie EDF und LLF zwar theoretisch eine optimale Ressourcenausnutzung und Flexibilität bei wechselnden Systemlasten, jedoch haben unsere Experimente gezeigt, dass diese Algorithmen in der Praxis oft Schwierigkeiten haben, alle Deadlines einzuhalten. Besonders unter hoher Last oder bei unvorhergesehenen Ereignissen können dynamische Algorithmen unvorhersehbare Verhaltensweisen zeigen, die zu verpassten Deadlines führen.
Zusammenfassend lässt sich sagen, dass die Wahl des richtigen Scheduling-Algorithmus für Echtzeitsysteme eine sorgfältige Analyse der spezifischen Anforderungen und Einschränkungen des jeweiligen Systems erfordert. Es gibt keine “Einheitslösung”, sondern es muss eine maßgeschneiderte Lösung entwickelt werden, die die zeitlichen Anforderungen, Systemressourcen und spezifischen Anwendungsszenarien optimal berücksichtigt. Unsere Experimente legen nahe, dass Fixed-Priority Scheduling eine verlässliche Wahl für Systeme ist, die strikte Deadline-Anforderungen haben, während dynamische Algorithmen eher für weniger kritische oder flexible Anwendungsfälle geeignet sind.
Quellen¶
A comparative study of rate monotonic schedulability tests, Nasro Min-Allah · Samee Ullah Khan · Nasir Ghani · Juan Li · Lizhe Wang · Pascal Bouvry
Real-Time Embedded Components and Systems with Linux and RTOS, Sam Siewert · John Pratt
Schedulingstrategien für Echtzeitsysteme, Horst Schirmeier
C. L. Liu and J. W. Layland. 1973. Scheduling Algorithms for Multiprogramming in a Hard-Real-Time
Environment. J. ACM 20, 1 (January 1973), 46-61. http://dx.doi.org/10.1145/321738.321743
https://en.wikipedia.org/wiki/Inverted_pendulum
https://www.amd.e-technik.uni-rostock.de/veroeff/scopell.pdf
https://www.tutorialspoint.com/rate-monotonic-scheduling
https://www.informatik.hu-berlin.de/de/forschung/gebiete/rok/teaching/WS/EMES/Slides/03-priority_scheduling.pdf
https://www.youtube.com/watch?v=F321087yYy4