Versuch 1: Ansible
1 Motivation
In der Praxis wächst der Bedarf an der Automatisierung wiederkehrender Aufgaben stetig. Ansible, eine Open-Source-Software, bietet sich hierfür als vielseitiges Werkzeug an. Dank seiner guten Skalierbarkeit können Anwendungen und Konfigurationen, wie das initiale Einrichten von Mitarbeiter-Notebooks, auf vielen Maschinen gleichzeitig und identisch durchgeführt werden. Auch wiederkehrende Aufgaben, wie das Aktualisieren von apt-Paketen, lassen sich durch die einfache Syntax mit YAML-Dateien schnell und effizient umsetzen. Durch die große Community wird Ansible stets verbessert und findet auch Einsatz in der Industrie.
2 Was ist Ansible?
Ansible ist ein Open Source Automatisierungs-Tool das durch Simplizität und Kompabilität glänzt.
Durch das einfache, lesbare Skript in YAML-Struktur können in kürzester Zeit viele Aufgaben automatisiert werden. So kann zum Beispiel Software installiert, aktualisiert oder gelöscht werden. Zudem können beispielsweise Shell Skripts ausgeführt werden oder Konfigurationsaufgaben durchgeführt werden.
Ansible muss dafür nicht auf der Ziel Maschine installiert werden, sondern lediglich auf dem eigenen Endgerät, es ist also eine sogenannte “Agent-less Architecture”. Die gesamte Kommunikation erfolgt über SSH oder WinRM um Tasks auszuführen.
Ein regelmäßiges Ausführen der selben Skripts ist auch ohne möglich, da der gewünschte Zielzustand auch bei Mehrfachausführung nicht verlassen wird sondern diese Tasks stattdessen übersprungen werden.
2.1 Wichtige Begriffe
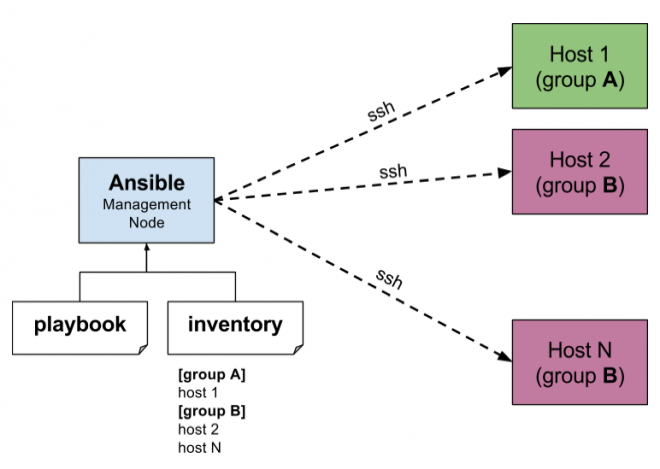
Control Node = Eine Maschine die Ansible ausführt und die Playbooks ausführt
Managed Node = Eine Zielmaschine, auf der Tasks executed werden
Inventory = Ein YAML-File das eine Liste von Hosts spezifiziert, wobei auch eine Gruppierung möglich ist.
Role = Eine Sammlung von Playbooks, Variablen, Tasks und anderen Ansible-Artefakten, die zusammengefasst werden, um eine bestimmte Funktion oder Konfiguration zu erfüllen.
Playbook = Ein YAML-File das die Zugriffsart (zum Beispiel Systemrolle) und die zu erledigenden Tasks festlegt.
Task = Eine Aufgabe wie zum Beispiel das Installieren eines apt-Pakets oder das Ausführen eines Shell Skripts
Variable = Platzhalter, die in Playbooks und Templates verwendet werden, um dynamische und wiederverwendbare Konfigurationen zu ermöglichen. So können zum Beispiel in Playbooks zurückgegebene Werte in Variablen gespeichert und später wiederverwendet werden.
Facts = Metadaten die von Ansible gesammelt werden, zum Beispiel IP-Adresse und Betriebssystemversion
3 Installation
Die Installation ist sehr simpel und kann unter Verwendung von apt einfach mit
sudo apt install ansibledurchgeführt werden.
Alternativ kann Ansible auch mit pip in ein Virtuelles Python Environment installiert werden.
4 Ansible Inventory:
Das Inventory ist eine Datei, die eine Liste der Hosts (Server, VMs, Geräte) enthält, auf denen Ansible Aufgaben ausführen soll. Es definiert, welche Systeme Ansible verwalten soll und welche Konfigurationen oder Variablen für diese Hosts gelten. Die Systeme, die als Hosts definiert werden, können in Gruppen unterteilt werden, sodass spezifische Aufgaben nur auf bestimmte Systeme angewendet werden.
Ansible unterstützt zwei Formate für das Erstellen des Inventories: INI und YAML.
Das INI-Format ist sehr einfach und basiert auf einer minimalistischen Syntax, wie sie im folgenden Beispiel zu sehen ist.
INI-Beispiel:
[webserver]
web01 ansible_host=192.168.1.10 ansible_user=root
web02 ansible_host=192.168.1.11 ansible_user=root
[dbserver]
db01 ansible_host=192.168.1.20 ansible_user=rootDas YAML-Format bietet mehr Struktur, was zu mehr Flexibilität und Komplexität führt. Dadurch können, wie im folgenden Beispiel, Hierarchien zwischen den Hostgruppen erstellt werden.
YAML-Beispiel:
all:
hosts:
web01:
ansible_host: 192.168.1.10
ansible_user: root
web02:
ansible_host: 192.168.1.11
ansible_user: root
children:
dbserver:
hosts:
db01:
ansible_host: 192.168.1.20
ansible_user: root5 Ad-hoc-Befehle:
5.1 Was sind Ad-Hoc-Befehle in Ansible?
Ad-Hoc-Commands sind einmalige Befehle, die mit ansible direkt über die Kommandozeile ausgeführt werden. Sie sind nützlich, wenn man schnelle Aufgaben auf mehreren Servern gleichzeitig erledigen möchte, ohne dafür ein Playbook schreiben zu müssen.
Man könnte meinen, das widerspricht dem eigentlichen Zweck von Ansible, nämlich Aufgaben zu automatisieren und wiederverwendbar zu machen. Aber gerade Ad-Hoc-Kommandos können eindrucksvoll zeigen, wie leistungsfähig Ansible ist und was sich damit spontan erledigen lässt.
5.2 Einfaches Beispiel
Nehmen wir an, wir haben eine inventory.ini mit folgenden Gruppen:
[webservers]
192.168.10.11
192.168.10.12
[VMs]
192.168.20.21
192.168.20.22Wenn wir nun nur die Webserver anpingen möchten, können wir folgenden Befehl verwenden:
ansible webservers -i inventory.ini -m pingDieser Befehl führt das ping-Modul -m nur auf den Hosts in der Gruppe [webservers] aus. So lässt sich schnell überprüfen, ob die Zielsysteme erreichbar sind. Die Ausgabe könnte so aussehen:
192.168.10.11 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.10.12 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: Connection timed out",
"unreachable": true
}5.3 Fortgeschrittenes Beispiel
Der folgende Ad-Hoc-Befehl installiert das Paket htop auf allen Servern, die in der Gruppe [VMs] der Datei inventory.ini definiert sind.
ansible VMs -i inventory.ini -m apt -a "name=htop state=present" -u ubuntu -b -K| Option | Bedeutung |
|---|---|
| VMs | Zielgruppe aus der inventory.ini |
| -i inventory.ini | Gibt die verwendete Inventory-Datei an |
| -m apt | Verwendet das apt-Modul für Paketverwaltung auf Debian/Ubuntu-Systemen |
| -a “name=htop state=present” | Modulargumente: name=htop ist das zu installierende Paket, state=present stellt sicher, dass es installiert ist |
| -u ubuntu | Führt den Befehl mit dem Benutzer ubuntu auf den Zielsystemen aus |
| -b | (become) Führt den Befehl mit Root-Rechten aus |
| -K | Fordert die Eingabe des sudo-Passworts an |
Beispel Ausgabe, wenn der Befehl erfolgreich war. Die Zeile "changed": true zeigt an, dass Ansible auf dem jeweiligen Host tatsächlich etwas verändert hat. In diesem Fall wurde das Paket htop installiert.
192.168.20.21 | CHANGED => {
"cache_update_time": 1743625073,
"cache_updated": false,
"changed": true,
[...]
}
192.168.20.22 | CHANGED => {
"cache_update_time": 1743625073,
"cache_updated": false,
"changed": true,
[...]
}5.4 Idempotenz
Idempotenz ist ein zentrales Prinzip von Ansible und eine der wichtigsten Eigenschaften, die es von klassischen Shell-Skripten unterscheidet.
Ein Befehl oder eine Aufgabe ist idempotent, wenn sie beliebig oft wiederholt werden kann, ohne dass sich das Ergebnis verändert, solange sich am Systemzustand nichts geändert hat.
Wenn wir denselben Ad-Hoc-Befehl wie vorher noch einmal ausführen:
ansible VMs -i inventory.ini -m apt -a "name=htop state=present" -u ubuntu -b -Ksoll die Ausgabe dann zum Beispiel so aussehen:
192.168.20.21 | SUCCESS => {
"changed": false
[...]
}
192.168.20.22 | SUCCESS => {
"changed": false
[...]
}Die Zeile "changed": false bedeutet, dass Ansible keine Änderungen am Zielsystem vorgenommen hat, weil der gewünschte Zustand bereits erfüllt war.
6 Playbooks:
Ein Playbook ist eine YAML-Datei, die eine oder mehrere Plays enthält, die nacheinander auf die gewünschten Zielhosts ausgeführt werden. Playbook Beispiel:
- name: Installiere Vim
hosts: all
become: yes
tasks:
- name: Vim installieren
apt:
name: vim
state: latestIn diesem Beispiel wird auf allen Hosts per apt der Editor Vim installiert. Das Playbook besteht aus einem Play, das eine Task umfasst. Wenn man ein weiteres Play hinzufügen möchte, kann man dies problemlos tun, indem man einfach einen weiteren Abschnitt unterhalb des ersten Plays einfügt.
Um das Playbook auszuführen, muss der folgende Befehl verwendet werden:
ansible-playbook -i inventory.ini playbook.yaml
Dabei gibt inventory.ini die Hosts an, auf denen das Playbook ausgeführt werden soll, und playbook.yaml ist die Datei, die das Playbook enthält.
7 Ansible Rollen:
Ansible-Rollen dienen dazu, Automatisierungsaufgaben in modulare, wiederverwendbare Komponenten zu strukturieren. Diese Strukturierung macht den Automatisierungscode skalierbar und einfacher zu warten.
7.1 Vorteile
Eine geschriebene Ansible-Rolle kann in mehreren Projekten verwendet werden (Wiederverwendbarkeit) und trennt die Logik in strukturierte Komponenten (Wartbarkeit). Sie ermöglicht es, komplexen Code und komplexe Infrastruktur effizient zu verwalten (Skalierbarkeit) und trägt dazu bei, Playbooks übersichtlich und lesbar zu halten (Lesbarkeit).
7.2 Struktur einer Rolle in Ansible
7.2.1 Eine Rolle erstellen
Eine neue Rolle kann mit dem Befehl ansible-galaxy init <Rollenname> erzeugt werden, zum Beispiel:
ansible-galaxy init example_roleDies erzeugt die Rolle im Ordner example_role mit folgender Struktur:
example_role
│
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml7.2.2 Dateien und ihre Aufgaben
Die folgende Tabelle dient dazu, zu erklären, wofür jedes Verzeichnis und die jeweils enthaltene main.yml-Datei gedacht ist:
| Verzeichnis | Beschreibung |
|---|---|
defaults/ |
Enthält Standardvariablen mit der niedrigsten Priorität. |
files/ |
Beinhaltet statische Dateien, die auf Zielsysteme kopiert werden können. |
handlers/ |
Definiert Handler, die durch notify-Aufrufe im Playbook ausgelöst werden. |
meta/ |
Enthält Metadaten über die Rolle. |
tasks/ |
Hauptverzeichnis für Aufgaben/Anweisungen. |
templates/ |
Beinhaltet Jinja2-Templates, die dynamisch generiert werden. |
tests/ |
Enthält Test-Playbooks und ein einfaches INventory zur Testausführung. |
vars/ |
Beinhaltet Variablen mit höherer Priorität als defaults/. |
README.md |
Dokumentation der Rolle, optional aber empfohlen. |
Jede Rolle muss mindestens eines dieser Verzeichnisse enthalten, um als gültige Rolle zu gelten. Verzeichnisse, die von der Rolle nicht verwendet werden, können weggelassen werden.
7.3 Struktur eines Ansible-Projekts
Um am besten zu zeigen, wie ein Ansible-Projekt aufgebaut ist, demonstrieren wir die Einrichtung eines Projekts mit einer einfachen Rolle, die nginx installiert, startet und aktiviert.
Zunächst muss die Verzeichnisstruktur erstellt werden. Das kann mit den folgenden Befehlen erfolgen:
mkdir -p ansible-nginx/{inventory,playbooks,roles/nginx/{tasks,handlers,templates,files,vars,defaults,meta}}
touch ansible-nginx/{ansible.cfg,playbooks/main.yml,inventory/inventory.ini}
cd ansible-nginx
ansible-galaxy init roles/nginxDie Verzeichnisstruktur nach Ausführung der oben genannten Befehle sollte wie folgt aussehen:
ansible-nginx
│
├── ansible.cfg
├── inventory
│ └── inventory.ini
├── playbooks
│ └── main.yml
└── roles
└── nginx
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.ymlDamit Ansible sich ohne Passwortabfrage auf den Zielsystemen anmelden kann, sollte eine SSH-Schlüsselauthentifizierung eingerichtet werden.
SSH-Schlüssel erzeugen (falls noch nicht vorhanden):
ssh-keygen -f ~/.ssh/ansible_key -t rsa -b 4096Danach den Anweisungen im Terminal folgen.
Öffentlichen Schlüssel auf das Zielsystem kopieren:
ssh-copy-id -i ~/.ssh/ansible_key.pub <user>@<ip_of_target>Verbindung testen:
ssh <user>@<ip_of_target>In der Datei inventory/inventory.ini werden die Zielsysteme festgelegt:
[webservers]
web1 ansible_host=<ip_of_target> ansible_user=<Benutzername auf dem Zielsystem>Standardvariablen für die Rolle werden in roles/nginx/defaults/main.yml definiert:
nginx_listen_port: 80In roles/nginx/tasks/main.yml werden die Aufgaben zum Installieren und Starten von Nginx definiert:
- name: Install Nginx
ansible.builtin.apt:
name: nginx
state: present
update_cache: yes
- name: Copy Nginx Configuration
ansible.builtin.template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify: Restart Nginx #Hier benötigen wir ein Händler
- name: Start and Enable Nginx
ansible.builtin.systemd:
name: nginx
state: started
enabled: yesDer Handler wird in roles/nginx/handlers/main.yml definiert.
Handler werden von Tasks ausgelöst, die sie über notify benachrichtigen, wie zum Beispiel die vorherige Aufgabe Copy Nginx Configuration.
- name: Restart Nginx
ansible.builtin.systemd:
name: nginx
state: restartedCreate a Template for Nginx Configuration roles/nginx/templates/nginx.conf.j2
server {
listen {{ nginx_listen_port }};
server_name _;
location / {
root /var/www/html;
index index.html;
}
}Das Template für die Nginx-Konfiguration wird in roles/nginx/templates/nginx.conf.j2 erstellt.
- name: Configure Web Servers
hosts: webservers
become: yes
roles:
- nginxAbschließend wird die Konfigurationsdatei ansible.cfg benötigt, um einige Standardeinstellungen festzulegen:
[defaults]
inventory = inventory/inventory.ini
roles_path = roles/Nun ist unsere Rolle fertig und wir können das Playbook vom Projekt-Hauptverzeichnis /ansible-nginx aus mit folgendem Befehl ausführen:
ansible-playbook playbooks/main.ymlDas Playbook wird nun ausgeführt, und nginx wird auf dem bzw. den in der Inventory-Datei definierten Server(n) bzw. VM(s) installiert und gestartet.
Die erfolgreiche Ausführung kann überprüft werden, indem die folgende Adresse im Browser aufgerufen wird:
http://<ip_of_target>8 Qualitätsanalyse und Fehlercharakterisierung in Open-Source-Ansible-Skripten
Die Praxis des Infrastructure as Code (IaC) hat sich in den letzten Jahren als wesentlicher Bestandteil der modernen IT-Automatisierung etabliert. Dabei wird Infrastruktur nicht mehr manuell konfiguriert, sondern deklarativ in Form von Code beschrieben. Dies ermöglicht eine reproduzierbare, versionierbare und skalierbare Verwaltung von Servern, Netzwerken und Diensten.
Trotz dieser Vorteile zeigen aktuelle Studien, dass viele Herausforderungen im Bereich der Qualitätssicherung bestehen bleiben. Diese Arbeit widmet sich daher der systematischen Analyse der Qualität von Ansible-Skripten im Open-Source-Kontext. Im Mittelpunkt stehen drei zentrale Aspekte: die Qualität von Testskripten, die Ausführbarkeit von Playbooks und der Umgang mit Variablen. Die Grundlage bilden drei empirische Studien, die jeweils einen dieser Aspekte im Detail untersuchen.
8.1 Testqualität in Ansible-Skripten
Die Studie von Hassan et al. (2022) \({\color{green}\text{[1]}}\) untersucht die Testqualität in Ansible-Testskripten und führt eine systematische Kategorisierung von Fehlern durch. Ausgewertet wurden 4.831 Testskripte aus 104 Open-Source-Repositories und über 2.606 commits mittels qualitativer Inhaltsanalyse (Open Coding). Ziel war es, die Häufigkeit und Art von Fehlern in diesen Skripten zu identifizieren und wiederkehrende problematische Muster („Test-Smells“) aufzudecken.
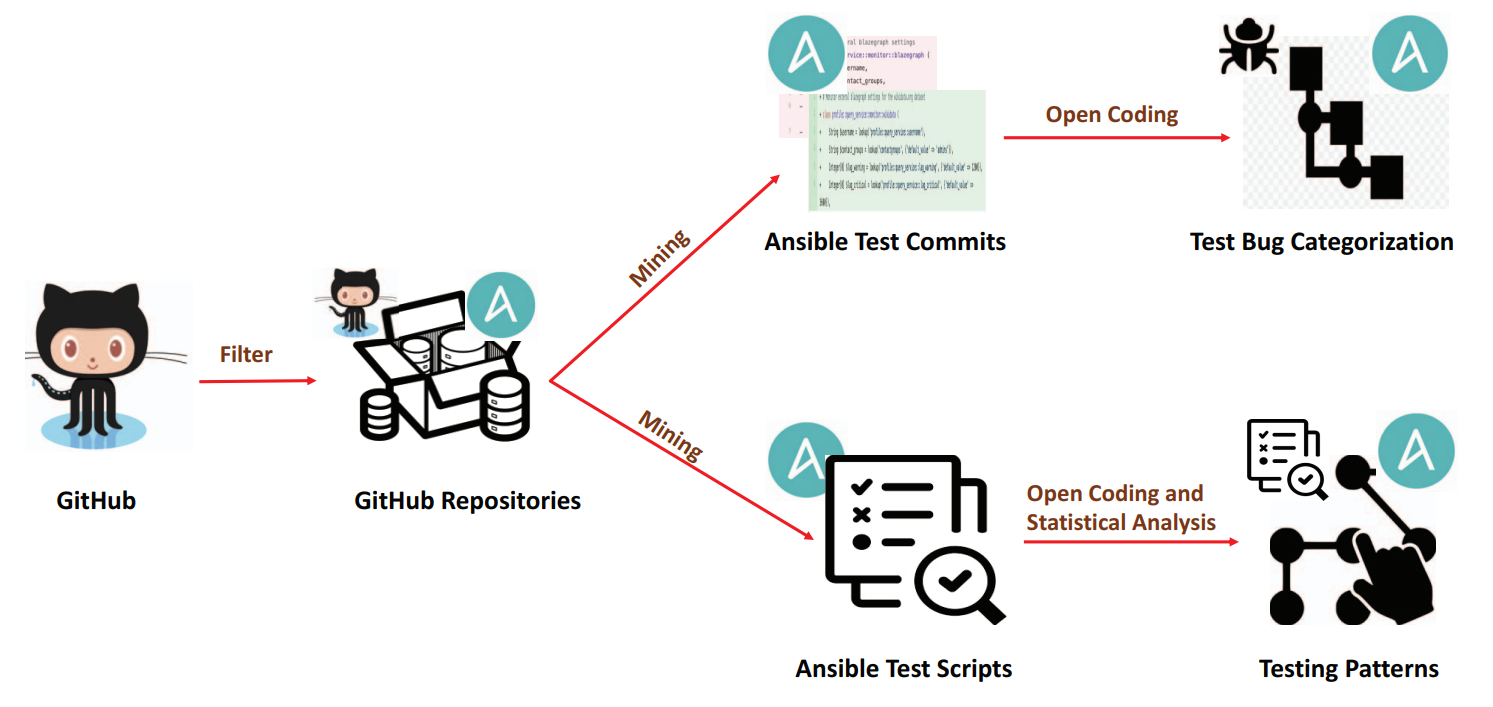
Die Ergebnisse zeigen, dass etwa 1,8 % der Testskripte mindestens einen Fehler enthalten. Besonders bemerkenswert ist, dass in fast der Hälfte aller untersuchten Repositories (45,2 %) fehlerhafte Testskripte vorkommen.
Die analysierten Fehler lassen sich in sieben Kategorien einteilen, darunter Sicherheits-, Performance- und Konfigurationsprobleme. Darüber hinaus identifizierten die Autoren drei typische Test-Smells, die häufig mit Fehlern korrelieren:
- Assertion Roulette: Mehrere Assertions in einem einzigen
assert-Block, erschweren das Debugging. - Local Only Testing: Tests, die ausschließlich lokal ausgeführt werden, ohne die Zielumgebung realistisch abzubilden.
- Remote Mystery Guest: Versteckte Abhängigkeiten zu externen Hosts oder Services (z. B. via
get_url).
Diese Muster erschweren das Troubleshooting, gefährden die Reproduzierbarkeit und beeinträchtigen die Zuverlässigkeit der Infrastruktur.
8.2 Ausführbarkeit von Ansible-Playbooks
Die Arbeit von Mendis et al. (2024) \({\color{green}\text{[2]}}\) untersucht die Executability von Ansible-Playbooks, also die Frage, ob öffentlich verfügbare Skripte tatsächlich ohne Fehler ausführbar sind. In einer empirischen Analyse wurden 2.952 Playbooks aus 56 Repositories mithilfe eines kontrollierten Execution Harness getestet. Für die nicht erfolgreich ausgeführten Playbooks (2.110 Stück) wurden detaillierte Crash Reports gesammelt und mittels Open Coding analysiert, einer qualitativen Methode zur Identifikation von wiederkehrenden Fehlerkategorien. Daraus wurden vier Fehlerklassen und 30 spezifische Fehlertypen abgeleitet.
Das Ergebnis ist alarmierend: Nur 28,5 % der Playbooks konnten ohne Fehler ausgeführt werden. Die restlichen 71,5 % verursachten beim Ausführen mindestens eine Fehlermeldung. Die identifizierten Fehler wurden in vier Hauptkategorien unterteilt:
- Umgebungsabhängige Fehler (z. B. fehlende Rollen oder ungültige Hosts),
- Verwendung veralteter Komponenten,
- Semantische Fehler in der Playbook-Struktur, und
- Fehler bei Dateioperationen (z. B. fehlende Templates oder Berechtigungen).
Diese Ergebnisse zeigen deutlich, dass viele Open-Source-Playbooks entweder veraltet oder schlecht dokumentiert sind, ein erhebliches Risiko für die Wiederverwendbarkeit.
8.3 Probleme im Umgang mit Variablen
Die Studie von Opdebeeck et al. (2022) \({\color{green}\text{[3]}}\) beschäftigt sich mit sogenannten Smelly Variables – problematischen Variablenverwendungen in Ansible, die durch komplexe Semantik entstehen. Im Fokus stehen dabei insbesondere die Variablenpräzedenz und die Lazy Evaluation von Templates.
Die Autoren identifizieren sechs neuartige Code-Smells im Umgang mit Variablen, etwa durch unklare Überschreibungen, mehrfach ausgewertete Ausdrücke oder Seiteneffekte durch zufällige Werte. In 21.931 untersuchten Rollen fanden sie, dass 19,4 % der Rollen mindestens eine Instanz eines der sechs definierten Code Smells aufweisen. Insgesamt wurden 31.334 einzigartige Smells identifiziert. Besonders häufig traten Variablen auf, die mit einer unnötig hohen Präzedenz definiert wurden (z. B. durch set_fact), sowie unbedingte Überschreibungen bestehender Definitionen. Ein zentrales Problem: Viele dieser Variablenprobleme bleiben über lange Zeit unentdeckt und werden selten behoben. Noch beunruhigender ist, dass neue Commits häufiger neue Smells einführen als bestehende beseitigen.
Die Autoren betonen die Notwendigkeit, tiefergehende Analysetools zu entwickeln, die über einfache Linter hinausgehen etwa mithilfe von Program Dependence Graphs (PDG), die Daten- und Kontrollflüsse nachvollziehbar machen.
8.4 Codegenerierung mit Ansible Lightspeed: Eine neue Perspektive auf Qualität und Akzeptanz
Mit der zunehmenden Komplexität moderner IT-Infrastrukturen und dem Wachstum von Infrastructure as Code-Praktiken steigt auch der Bedarf an intelligenten Assistenzsystemen, die Entwickler bei der Erstellung und Pflege von Konfigurationsskripten unterstützen. In diesem Kontext stellt Ansible Lightspeed eine vielversprechende Entwicklung dar: ein auf Large Language Models (LLMs) basierender Code Completion Service, der speziell für die Domäne von Ansible entwickelt wurde.
Die Arbeit von Sahoo et al. (2024) \({\color{green}\text{[4]}}\) liefert erstmals umfassende empirische Einblicke in die Nutzung eines solchen domänenspezifischen Codegenerierungstools auf Basis von realen Daten von über 10.000 Nutzer. Ziel der Studie war es, die Akzeptanz, Nutzungsdauer und Bearbeitungsintensität der von Ansible Lightspeed vorgeschlagenen Code-Snippets systematisch zu untersuchen.
Die Nutzerbindungsrate (N-Day Retention) ist ein etablierter Indikator für die langfristige Relevanz eines Tools im Entwicklungsalltag. Für Ansible Lightspeed konnte eine bemerkenswerte Day-30-Retention von 13,66 % festgestellt werden – signifikant höher als vergleichbare Raten bei generischen Code Completion Tools (z. B. 4,13 % für iOS-Apps). Dies deutet darauf hin, dass Lightspeed vor allem im professionellen Umfeld produktiv eingesetzt wird. Unterstützt wird diese Annahme durch die Beobachtung, dass die Nutzung an Werktagen deutlich höher ausfällt als an Wochenenden.
Die initiale Akzeptanzrate der generierten Vorschläge liegt bei 65,9 %, jedoch ist dieser Wert allein nicht aussagekräftig über den tatsächlichen Nutzen der Vorschläge. Durch die Einführung der sogenannten Strong Acceptance Rate – welche nur Vorschläge berücksichtigt, die kaum oder gar nicht editiert wurden – ergibt sich ein realistischeres Bild: 49,1 % der Vorschläge wurden ohne oder mit nur geringfügigen Änderungen verwendet. Dies liegt deutlich über den Raten anderer Systeme wie GitHub Copilot (ca. 30 %).
Besonders aufschlussreich ist die Analyse der Bearbeitungen: Etwa 60 % der akzeptierten Vorschläge wurden ohne jegliche Modifikation übernommen, während etwa 6,6 % stark verändert und 18,1 % sogar wieder gelöscht wurden. Die häufigsten Anpassungen betrafen konkrete Werte, Moduloptionen oder die Umstrukturierung des YAML-Codes.
Im Zusammenspiel mit den zuvor beschriebenen Herausforderungen – Testqualität, Ausführbarkeit und Variablenmanagement – liefert Ansible Lightspeed eine neue Dimension zur Bewertung von Ansible-Skripten. Die hohe Akzeptanzrate und das positive Nutzerfeedback legen nahe, dass LLM-basierte Tools wie Lightspeed das Potenzial haben, die Erstellung von Infrastruktur-Code nachhaltiger, sicherer und effizienter zu gestalten.
9 Live Demo (Deploying GitLab CE to a VM)
10 References
- An Empirical Comparison of Code Generation Approaches for Ansible
- Smelly variables in ansible infrastructure code: detection, prevalence, and lifetime
- Evaluating the Quality of Open Source Ansible Playbooks: An Executability Perspective
- Insights from the Usage of the Ansible Lightspeed Code Completion Service