Versuch 3: KI Agenten
1 Einführung
Künstliche Intelligenz (KI) hat in den letzten Jahren signifikante Fortschritte verzeichnet und findet zunehmend Anwendung in verschiedenen Bereichen des täglichen Lebens und der Wirtschaft. Ein besonders vielversprechendes Gebiet ist der Einsatz von KI-Agenten, die dazu befähigt sind, komplexe Aufgaben autonom zu erledigen und menschliche Teams zu unterstützen. Diese Entwicklung ist sowohl in der Praxis als auch in der Forschung von großer Bedeutung und bietet ein breites Spektrum an Möglichkeiten zur Effizienzsteigerung und Kosteneinsparung. KI-Agenten erfahren derzeit eine zunehmende Verbreitung in Unternehmen, wo sie zur Ergänzung menschlicher Teams und zur Erledigung von Aufgaben rund um die Uhr beitragen. Als Beispiele können Google und Microsoft angeführt werden, die KI-Agenten zur Unterstützung ihrer Entwicklungsteams testen. Diese Agenten sind nicht nur in der Lage, einfache, wiederkehrende Aufgaben zu übernehmen, sondern auch komplexe kognitive Aufgaben zu bewältigen. Dazu gehören Entscheidungen in Echtzeit, die zu einer Beschleunigung von Prozessen in dynamischen Geschäftsumgebungen führen. Dies macht den Einsatz von KI-Agenten zu einem sehr praxisrelevanten Thema, da Unternehmen durch die Automatisierung bestimmter Aufgaben erhebliche Kosteneinsparungen erzielen können. Die Integration von KI-Agenten in den Arbeitsalltag bietet jedoch nicht nur wirtschaftliche Vorteile, sondern auch die Möglichkeit, die Arbeitsqualität zu verbessern. Durch die Übernahme routinemäßiger Aufgaben durch KI-Agenten können menschliche Mitarbeiter sich auf kreative und strategische Tätigkeiten konzentrieren, was zu einer höheren Arbeitszufriedenheit und Innovationskraft führen kann.
Die Forschung im Bereich KI-Agenten stellt ein noch sehr neues und dynamisches Feld dar, das zahlreiche Herausforderungen und Chancen bietet. Der Fokus wissenschaftlicher Arbeiten liegt auf der Entwicklung von Multi-Agenten-Systemen und Reinforcement Learning (RL)-Techniken. Diese Systeme sind in der Lage, den Retrieval-Prozess dynamisch anzupassen und die Qualität der generierten Antworten zu verbessern. Ein Beispiel hierfür ist die Forschung an wissenschaftlichen KI-Agenten, die als nützliche Werkzeuge in der Medikamentenentwicklung eingesetzt werden können. Die vorliegende Arbeit untersucht die Möglichkeit, dass diese Agenten die Steuerung von Robotern und komplexen Anlagen über natürliche Sprache ermöglichen. Es wird argumentiert, dass dies die Effizienz und Präzision in der Forschung erheblich steigern kann. Darüber hinaus existieren zahlreiche Forschungsprojekte, die sich mit den ethischen und normativen Herausforderungen des Einsatzes von KI-Agenten auseinandersetzen. Insbesondere im sensiblen Anwendungsbereich der Medizin ist es erforderlich, den Einsatz von KI-Agenten durch ethische Leitlinien zu regulieren, um die Sicherheit und das Vertrauen der Patienten zu gewährleisten.
Obwohl KI-Agenten zahlreiche Vorteile und Möglichkeiten bieten, ist es von entscheidender Bedeutung, die damit einhergehenden Herausforderungen und Risiken zu berücksichtigen. Hierzu zählen die Transparenzpflichten sowie die Haftung für Schäden, die durch KI-Agenten verursacht werden, sowie Datenschutzrechtliche Bedenken. Es obliegt den Unternehmen, die Kontrolle über die von ihnen eingesetzten KI-Agenten zu wahren und die Verantwortung für deren Handlungen zu übernehmen. Dies erfordert eine sorgfältige Implementierung und Überwachung der KI-Systeme, um potenzielle Risiken zu minimieren. Ein weiterer wichtiger Aspekt ist die Akzeptanz und das Vertrauen der Mitarbeiter und Kunden in die neuen Technologien. Es ist von entscheidender Relevanz, dass Unternehmen ihre Mitarbeiter im Umgang mit KI-Agenten schulen und ihnen die Vorteile und Möglichkeiten dieser Technologie vermitteln. Die erfolgreiche Integration von KI-Agenten in die genannte Umgebung kann folglich nur auf diese Art und Weise gewährleistet werden.
Nach dieser kurzen Einleitung in das Thema werden im Folgenden noch diese Kapitel näher betrachtet:
Begriffliche Grundlagen und Klassifikation: Diese Sektion legt die grundlegenden Begriffe und Konzepte dar, die für das Verständnis von KI-Agenten notwendig sind. Es wird eine Klassifikation der verschiedenen Arten von KI-Agenten vorgenommen.
Model Context Protocol (MCP): Hier wird das Model Context Protocol erläutert, ein wichtiger Standard für die Kommunikation und das Management von KI-Agenten.
Lokale Open-Source LLMs und ihr Betrieb: Diese Sektion befasst sich mit der Implementierung und dem Betrieb lokaler Open-Source-Sprachmodelle (LLMs) und deren Vorteile gegenüber zentralisierten Lösungen.
Anwendungsfälle: Abschließend werden konkrete Anwendungsfälle von KI-Agenten in verschiedenen Branchen und Szenarien vorgestellt, um das theoretische Wissen in die Praxis zu übertragen.
2 Begriffliche Grundlagen und Klassifikation
AI-Agenten sind Systeme, die autonom Aufgaben im Auftrag eines Benutzers oder eines anderen Systems ausführen können, indem sie ihren Arbeitsablauf entwerfen und verfügbare Werkzeuge nutzen \({\color{green}\text{[1]}}\). Im Gegensatz zu traditionellen KI-Systemen, die vordefinierte Algorithmen innerhalb bestimmter Grenzen ausführen, besitzen AI-Agenten die Fähigkeit, ihre Umgebung autonom zu erfassen, zu analysieren und darauf zu reagieren, wobei sie ihr Verhalten basierend auf Umweltfeedback und gesammelter Erfahrung anpassen können.
Moderne AI-Agenten integrieren große Sprachmodelle (LLMs) mit spezialisierten Modulen für Wahrnehmung, Planung und Werkzeugnutzung \({\color{green}\text{[1, S. 1, 7-8, 12]}}\). Diese Integration ermöglicht es den Agenten, komplexe Aufgaben zu bewältigen, die über die Fähigkeiten traditioneller KI-Systeme hinausgehen.
Ein KI-Agent besteht typischerweise aus mehreren Kernkomponenten \({\color{green}\text{[2, S. 2-3]}}\):
- Wahrnehmungskomponente: Erkennt die Umgebung (z. B. durch Sensoren, Spracheingabe oder Textdaten).
- Planungskomponente: Entwickelt Strategien und Pläne, um ein Ziel zu erreichen.
- Aktionskomponente: Führt konkrete Handlungen aus.
- Gedächtnis/Erinnerung: Speichert frühere Erfahrungen oder Informationen zur Kontextanpassung.
- Werkzeugintegration: Nutzt externe Tools wie Suchmaschinen, Rechentools oder APIs zur Handlungsausführung.
Insbesondere moderne Agenten basieren auf Large Language Models (LLMs), die als zentrales Denkmodul fungieren und durch spezialisierte Werkzeuge und Umgebungsmodelle ergänzt werden \({\color{green}\text{[3]}}\)
2.1 Klassifikation von KI-Agenten
Nach Autonomiegrad
- Task-spezifische Agenten: Erfüllen klar definierte Aufgaben mit begrenztem Handlungsspielraum (z. B. Web-Scraping-Agenten).
- Generalistische Agenten: Passen sich flexibel an neue Aufgaben an, z. B. durch Zero-/Few-Shot-Lernen \({\color{green}\text{[5]}}\)
Nach Modularität
- Monolithische Agenten: Besitzen integrierte Entscheidungslogik ohne trennbare Module.
- Modulare Agenten: Trennen Fähigkeiten wie Wahrnehmung, Gedächtnis, Toolnutzung, eine Architektur, die Skalierbarkeit und Flexibilität erhöht \({\color{green}\text{[6]}}\).
Nach Interaktivität
- Single-Agent-Systeme: Agieren isoliert.
- Multi-Agent-Systeme: Interagieren mit anderen Agenten, z. B. in sozialen Simulationen oder kollaborativen Aufgaben \({\color{green}\text{[4]}}\).
Nach Zweck bzw. Anwendung
- Forschungsagenten: z. B. Agent Laboratory zur Automatisierung wissenschaftlicher Arbeiten \({\color{green}\text{[3]}}\).
- Simulative Agenten: z. B. Generative Agents zur realitätsnahen Modellierung menschlichen Verhaltens \({\color{green}\text{[4]}}\).
- Nutzerassistenz-Agenten: z. B. Chatbots oder Task-Manager in Produktivitätsumgebungen.
Nach Interaktionsmodalität
- Textbasierte Agenten: Kommunizieren primär über Sprache (z. B. GPT-Agenten).
- Multimodale Agenten: Kombinieren Text, Bild, Video oder Audio zur Wahrnehmung und Ausgabe \({\color{green}\text{[2]}}\).
3 Model Context Protocol (MCP)
Das Model Context Protocol (MCP) ist ein offenes, standardisiertes Protokoll zur Integration von KI-Systemen mit externen Tools, APIs und Datenquellen \({\color{green}\text{[7, 8]}}\). Es wurde Ende 2024 von Anthropic eingeführt und orientiert sich strukturell am Language Server Protocol (LSP). Im Unterschied zu manuellen API-Anbindungen oder proprietären Plugin-Systemen ermöglicht MCP eine modulare und plattformunabhängige Kommunikation zwischen KI-Anwendungen und externen Komponenten.
3.1 MCPs Architektur
MCP Verwendet eine Client Server Architektur \({\color{green}\text{[8, S. 4-5]}}\), wobei sich die Clients innerhalb eines Hosts befinden. Hosts sind hierbei LLM Anwendungen.wie Claude Desktop, IDE’s oder andere AI Tools. Clients wiederum maintainen die Verbindungen der Hosts zum MCP Server. CLients können Verbindungen zu mehreren Hosts aufbauen. Server stellen Tools, vorgefertigte Prompts und Kontext bereit und können sich auf dem lokalen System oder befinden oder remote über das Internet erreicht werden.
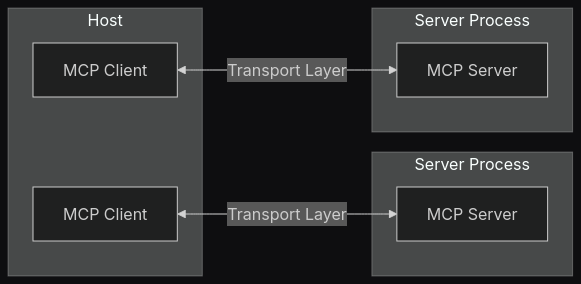
3.2 Kernkomponenten von MCP
3.2.1 Protokollschicht
Die Protokollschicht definiert Schlüßeklassen wie ‘Protocol’, ‘Client’ und ‘Server’.
3.2.2 Transportschicht
Sie ist zuständig für die tatsächliche Kommunikation zwischen Client und Server \({\color{green}\text{[8, S. 6]}}\). Zum Austausch von Nachrichten wird das JSON Format verwendet. Aktuell werden zwei Arten von Transportmechansimen verwendet: 1. Stdio transport: Ideal für lokale Prozesse, verwendet standard input/output für die Kommunikation 2. HTTP with SSE (Server-Sent Events) transport
3.2.3 Message Types
- Requests: Sind Anfragen, auf die eine Antwort erwartet wird
- Results: Sind erfolgreiche Antworten auf Anfragen
- Errors: Zeigen an, dass ein Anfrage fehlgeschlagen ist
- Notifications: Einwegnachrichten, die keine Antworten erwarten
3.3 Verbindungslebenszyklus
Die Verbindungsinitialisierung \({\color{green}\text{[8, S. 6-7]}}\) beginnt mit einem Initialisierungsrequest. Daraufhin antwortet der Server mit seiner Protocolversion und seinen c apabilities. Nach Empfang der Response sendet der Client eine ‘initialized’ Notificaion Die Verbindungsinitialisierung ist in Abbildung 2 dargestellt.
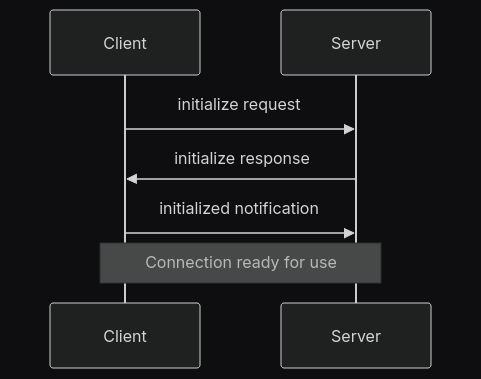
Nach der Initialisierung kann der Nachrichtenaustausch beginnen: In dieser Phase werden Requests, Responses und Notifications unterstützt. Jeder Kommunikationspartner kann jederzeit die Verbidung mit einem Aufruf der close() Funktion beenden. Außerdem kann die Verbindung durch einen Error beendet werden.
3.4 Error Handling
Folgende Errors werden durch das Error Enum bereitgestellt:
enum ErrorCode {
// Standard JSON-RPC error codes
ParseError = -32700,
InvalidRequest = -32600,
MethodNotFound = -32601,
InvalidParams = -32602,
InternalError = -32603
}3.5 Beispielimplementierung
Um das Model Context Protokoll zu verwenden muss das ensprechende Paket für die Sprache, in der es verwendet werden soll installiert werden. Verfügbare Sprachen sind Python, Node, Java, Kotlin und C#. Die folgende Beispielanwendung nutzt Python. Für Python kann das entsprechende Paket entweder über pip installiert werden oder es wird das Tool uv verwendet. uv ist ein in Rust geschriebener Python Paket- und Projektmanager, der von modelcontextprotocol empfohlen wird und von der Verwendung her an cargo erinnert.
# fedora
sudo dnf install nodejs npm uv
# Debianbasierte Systeme
sudo apt update
sudo apt install nodejs npm uv
# ab hier Vorgehen für fedora und Debian gleich
uv init mcp-server-demo
cd mcp-server-demo
uv add "mcp[cli]"Eine Beispiel implementierung eines Servers, der Zahlen addieren und grüßen kann:
# server.py
from mcp.server.fastmcp import FastMCP
from mcp.types import TextResourceContents
mcp = FastMCP("Demo")
# Add an addition tool
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
# Add a dynamic greeting resource
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> TextResourceContents:
return TextResourceContents(
uri=f"greeting://{name}",
mimeType="text/plain",
text=f"Hello, {name}!"
)
if __name__ == "__main__":
mcp.run()Der MCP Server kann dann entweder direkt in Claude Desktop installiert werden oder zum Test mit dem mcp tool getestet werden. Das mcp tool kann über uv aufgerufen werden:
uv run mcp dev server.pyPassend zu dem Server, der Zahlen addiert, ist im folgenden nun ein Clientbeispiel, dass diesen Server anfrägt:
from mcp import ClientSession, StdioServerParameters, types
from mcp.client.stdio import stdio_client
import asyncio
# Einbindung des lokalen MCP-Servers
server_params = StdioServerParameters(
command="python",
args=["server.py"]
)
async def handle_sampling_message(message: types.CreateMessageRequestParams) -> types.CreateMessageResult:
return types.CreateMessageResult(
role="assistant",
content=types.TextContent(
type="text",
text="Hello from test model!",
),
model="test-model",
stopReason="endTurn",
)
async def run():
async with stdio_client(server_params) as (read, write):
async with ClientSession(
read, write, sampling_callback=handle_sampling_message
) as session:
await session.initialize()
tools = await session.list_tools()
print("Verfügbare Tools:", tools)
result = await session.call_tool(
"add", arguments={"a": 5, "b": 8}
)
print("Ergebnis:", result)
result = await session.read_resource("greeting://Alice")
if result.contents:
content = result.contents[0]
print("Greeting:", content.text)
else:
print("Keine Inhalte empfangen.")
if __name__ == "__main__":
asyncio.run(run())Da Client und Server zur Kommunikation Standard Input and Output verwenden und nicht http, wird im Client Beispiel keine Url des Servers angegeben, sondern nur die Datei zum Serevr. Der Client kann mit diesem Kommando aufgerufen werden und ruft dann für die Anfragen den Server auf:
uv run client.pyErgbenisoutput der Clientanfragen:
Verfügbare Tools: meta=None nextCursor=None tools=[Tool(name='add', description='Add two numbers', inputSchema={'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': ['a', 'b'], 'title': 'addArguments', 'type': 'object'}, annotations=None)]
INFO Processing request of type CallToolRequest server.py:534
Ergebnis: meta=None content=[TextContent(type='text', text='13', annotations=None)] isError=False
INFO Processing request of type ReadResourceRequest server.py:534
Greeting: {
"uri": "greeting://Alice",
"mimeType": "text/plain",
"text": "Hello, Alice!"
}4 Lokale Open‑Source‑LLMs und Ollama
4.1 Lokale Open‑Source‑LLMs
4.1.1 Einleitung
Lokale Open‑Source‑LLMs sind große Sprachmodelle (Large Language Models), die vollständig unter einer Open‑Source‑Lizenz verfügbar sind und auf der eigenen Hardware betrieben werden können. Im Unterschied zu Cloud‑basierten Angeboten verbleiben Modellgewichte, Eingaben und Ausgaben im eigenen Netzwerk, was vollständige Kontrolle und Transparenz erlaubt. Diese Modelle bilden die Grundlage für Anwendungen wie Chatbots, Textgenerierung, Übersetzungen oder kontextsensitive Automatisierungen.
4.1.2 Motivation
- Datenschutz & Compliance: Sensible oder personenbezogene Daten werden nicht an externe Server übertragen. Durch On‑Premise‑Betrieb lassen sich interne Sicherheitsrichtlinien und Datenschutzgesetze (z.B. DSGVO) leichter umsetzen.
- Latenz & Verfügbarkeit: Ohne Roundtrips ins Internet reagieren lokale Modelle mit minimaler Latenz, selbst bei instabiler oder fehlender Internetverbindung.
- Kostenkontrolle: Es entfallen wiederkehrende Cloud‑API‑Kosten. Einmalige Anschaffungskosten für Hardware amortisieren sich langfristig bei hohem Anfrageaufkommen.
- Flexibilität & Anpassbarkeit: Open‑Source‑Modelle können intern weiterentwickelt, feingetunt oder mit proprietären Daten angereichert werden.
4.1.3 Beispiel Auswahlkriterien für lokale LLMs
- Lizenz & Nutzungsbedingungen: Apache 2.0, MIT oder vergleichbare Lizenz, die kommerzielle Nutzung erlaubt.
- Modellgröße & Architektur: Anzahl der Parameter (z.B. 7 B, 13 B, 30 B, 70 B) und Struktur (Transformer‑Architektur, Decoder‑only).
- Inferenzleistung: Durchsatz (Token/Sekunde) und maximale Kontextlänge (z.B. 2 048 bis 32 000 Tokens).
- Hardware‑Anforderungen: Benötigter Arbeitsspeicher (RAM/VRAM), CPU vs. GPU‑Unterstützung..
- Community & Ökosystem: Aktive Weiterentwicklung, Plugins, Bibliotheken (z.B. Hugging Face, Ollama).
- Benchmark‑Ergebnisse: Ergebnisse auf Eval‑Benchmarks wie MMLU, GSM8K, HellaSwag.
Warum ist Inferenzleistung wichtig?
- Durchsatz (Token/Sekunde): Gibt an, wie viele Token das Modell pro Sekunde generieren oder verarbeiten kann. Ein hoher Durchsatz ist entscheidend für Anwendungen mit hohem Traffic (z.B. Chatbots oder Batch-Verarbeitung), da damit Wartezeiten minimiert und die Skalierbarkeit erhöht werden.
- Maximale Kontextlänge: Definiert den maximalen Umfang des Eingabetexts (z.B. 2 048 bis 32 000 Tokens), den das Modell in einer einzigen Anfrage berücksichtigen kann. Eine größere Kontextlänge ermöglicht die Verarbeitung langer Dokumente, detaillierter Dialoge oder komplexer Anweisungen ohne Verlust wichtigen Kontextes.
4.1.4 Überblick populärer Modelle
| Modell | Parameter | Kontextlänge | Lizenz | Besonderheiten |
|---|---|---|---|---|
| Qwen‑7B | 7 Mrd. | 8 K Tokens | Apache 2.0 | Ausgewogene Performance für Sprach‑ und Codeaufgaben |
| Llama 2 7B/13B | 7 Mrd. / 13 Mrd. | 4 K Tokens | MIT | Starkes Open‑Source‑Ökosystem, feintuningfreundlich |
| Falcon 7B/40B | 7 Mrd. / 40 Mrd. | 2 K / 4 K Tokens | Apache 2.0 | Optimiert für High‑Performance auf Consumer‑GPUs |
| Gemma 7B/13B | 7 Mrd. / 13 Mrd. | 8 K Tokens | Apache 2.0 | Effiziente Inferenz, geringerer Speicherbedarf |
| Mistral 7B | 7 Mrd. | 8 K Tokens | Apache 2.0 | State‑of‑the‑art in Zero‑Shot‑Aufgaben |
Beispielprofil: Llama 2 13B
- Architektur: Decoder‑only Transformer mit 28 Layern
- Kontextlänge: 4 096 Tokens
- Inferenz: ~15 Token/s (auf A100 40 GB)
- Lizenz: Business‑freundlich, kommerziell nutzbar
4.1.5 Hardware‑Anforderungen
| Komponente | Empfehlung für 7 B‑Modelle | Empfehlung für 13 B‑Modelle | Empfehlung für 40 B‑Modelle |
|---|---|---|---|
| GPU VRAM | ≥ 12 GB | ≥ 24 GB | ≥ 48 GB |
| GPU Typ | RTX 4090 / A5000 | RTX A6000 / A100 | A100 / H100 |
| CPU | 8‑Kern, 3.5 GHz+ | 16‑Kern, 3.0 GHz+ | 32‑Kern, 2.5 GHz+ |
| RAM | ≥ 32 GB | ≥ 64 GB | ≥ 128 GB |
4.1.6 Anwendungsfälle & Best Practices
- Chatbots: On-Premise‑Support für Kundenservice
- Dokumentenzusammenfassung: Vertrauliche Berichte intern analysieren
- Code‑Generierung: Unterstützung bei IDE‑Plug‑ins ohne externen Codeversand
- Forschungsexperimente: Schnellere Iteration ohne API‑Limits
4.1.7 Sicherheit & Datenschutzvorteile
- Keine Datenlecks: Keine Telemetrie an Dritte
- Netzwerkisolierung: Betrieb in Closed‑Loop‑Umgebungen möglich
- Zugriffskontrolle: Integration in IAM und interne Policies
4.1.8 Herausforderungen & Grenzen
- Ressourcenbedarf: Hoher VRAM‑ und RAM‑Verbrauch
- Wartungsaufwand: Updates, Patches und Sicherheitsfixes manuell verwalten
- Modell‑Drift: Eigene Datenbasis kann Bias verstärken und regelmäßige Neubewertung erfordern
4.2 Ollama
4.2.1 Einführung in Ollama
Ollama ist ein schlankes CLI-Tool zur einfachen Ausführung, Verwaltung und Bereitstellung von Open-Source-LLMs auf lokalen Maschinen \({\color{green}\text{[9, 10]}}\). Es vereint Modellverwaltung, Inferenz und API-Zugriff in einem einheitlichen Workflo. Ganz ohne Docker, Kubernetes oder komplizierte Setups.
Architektur und Funktionsweise:
Ollama besteht aus drei Hauptkomponenten:
- CLI: Modellverwaltung, Erstellung, Ausführung und Upload
- Engine: Schnelle lokale Inferenz mit Unterstützung für Quantisierung
- REST-API: Lokaler HTTP-Server zur Nutzung von Modellen in Anwendungen
Standardmäßig läuft die Engine auf localhost:11434, sobald ein Modell gestartet wird.
Verfügbare CLI-Befehle:
| Befehl | Beschreibung |
|---|---|
ollama pull |
Modell aus der Registry herunterladen (inkl. Quantisierungs‑Tag) |
ollama list |
Lokale Modelle anzeigen |
ollama show |
Details zu einem Modell |
ollama rm |
Modell entfernen (auch: remove) |
ollama run |
Modell interaktiv oder skriptbasiert starten |
ollama stop |
Laufende Instanz beenden |
ollama serve |
HTTP-Server manuell starten (optional, wird durch run ersetzt) |
ollama login |
Anmeldung bei privater Registry |
ollama create |
Eigenes Modell aus Modelfile erzeugen |
ollama push |
Modell in Registry hochladen |
ollama cp |
Modell duplizieren |
ollama ps |
Aktive Modelle und Prozesse anzeigen |
ollama version |
Version anzeigen |
ollama config |
Konfiguration anzeigen/ändern |
Installation auf Debian & Grundsetup:
- Systempakete installieren
sudo apt update
sudo apt install -y curl gnupg- Ollama installieren
curl -fsSL https://ollama.com/install.deb.sh | sudo bash
sudo apt install ollama- Erstkonfiguration
- Standardverzeichnis:
~/.ollama
- (Optional) API‑Token für private Registries setzen:
export OLLAMA_API_KEY="<token>"4.2.2 Modelle herunterladen & ausführen
Modelle verwenden Quantisierungs-Tags (z.B. llama3:q8_0):
# Modell mit Standardquantisierung
ollama pull llama3
# Modell mit INT8-Quantisierung
ollama pull llama3:q8_0
# Interaktive Ausführung
ollama run llama3Geladene Modelle findet man unter:
~/.ollama/models/
4.2.3 Eigene Modelle erstellen (Modelfile)
Erstelle ein Modelfile mit z. B.:
FROM llama3
PARAMETER temperature 0.7
PARAMETER num_ctx 8192
SYSTEM "Du bist ein hilfreicher Assistent."Dann erstellen:
ollama create mein-modell -f Modelfile4.2.4 REST-API & Integration
- Server starten
ollama run llama3Alternativ manuell über:
ollama serve llama3 --port 11434- API-Endpunkte
POST /api/generate: Textgenerierung
POST /api/chat: Chat-Interaktion
Curl-Beispiel:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Was ist ein KI-Agent?"
}'Python-Beispiel:
import requests
resp = requests.post("http://localhost:11434/api/generate", json={
"model": "llama3",
"prompt": "Was ist ein KI-Agent?"
})
print(resp.json()["response"])4.2.5 Nützliche Umgebungsvariablen
| Variable | Zweck |
|---|---|
OLLAMA_HOST |
Host/Port-Konfiguration |
OLLAMA_MAX_QUEUE |
Maximale Anzahl von API-Anfragen |
OLLAMA_MODELS |
Pfad zum Modellverzeichnis |
5 Anwendungsfälle
Die Einführung von KI-Technologien in der Softwareentwicklung hat in den letzten Jahren einen transformativen Einfluss auf die Art und Weise gehabt, wie Entwickler arbeiten. Insbesondere die Nutzung großer Sprachmodelle (Large Language Models, LLMs) zur Unterstützung bei der Programmierung hat einen regelrechten Paradigmenwechsel eingeleitet.
Dieses Kapitel befasst sich mit drei bedeutenden Entwicklungen in diesem Bereich: dem AI Agent in Cursor, der Interaktion mit Figma über das Model Context Protocol (MCP) sowie OpenHands als Open-Source-Alternative mit der Möglichkeit, verschiedene LLMs einzubinden.
5.1 Cursor Agent: Autonome KI-Unterstützung in der Softwareentwicklung
Cursor Agent \({\color{green}\text{[11]}}\) ist der standardmäßige und autonomste Modus im Code-Editor Cursor, konzipiert zur Bewältigung komplexer Programmieraufgaben mit minimaler Anleitung. Als KI-Agent verfügt er über alle Werkzeuge, um selbstständig Codebasen zu erkunden, Dokumentationen zu lesen, im Web zu recherchieren, Dateien zu bearbeiten und Terminal-Befehle auszuführen, um Aufgaben effizient zu erledigen.
Die Hauptfähigkeiten des Cursor Agents umfassen:
- Autonome Operation: Der Agent erkundet selbstständig die Codebasis, identifiziert relevante Dateien und nimmt notwendige Änderungen vor.
- Vollständiger Werkzeugzugriff: Er nutzt alle verfügbaren Tools zum Suchen, Bearbeiten, Erstellen von Dateien und Ausführen von Terminal-Befehlen.
- Kontextverständnis: Der Agent entwickelt ein umfassendes Verständnis der Projektstruktur und -abhängigkeiten.
- Mehrstufige Planung: Komplexe Aufgaben werden in handhabbare Schritte unterteilt und sequentiell ausgeführt.
Der Cursor Agent folgt einem systematischen Ansatz, der dem eines menschlichen Entwicklers ähnelt:
- Verständnis der Anforderung: Der Agent analysiert die Anfrage und den Kontext der Codebasis, um die Aufgabenanforderungen und -ziele vollständig zu verstehen.
- Erkundung der Codebasis: Er durchsucht die Codebasis, Dokumentationen und das Web, um relevante Dateien zu identifizieren und die aktuelle Implementierung zu verstehen.
- Planung der Änderungen: Basierend auf der Analyse unterteilt der Agent die Aufgabe in kleinere Schritte und plant die Änderungen.
- Ausführung der Änderungen: Der Agent nimmt die notwendigen Code-Modifikationen gemäß dem Plan vor, kann auch neue Bibliotheken vorschlagen und Terminal-Befehle ausführen.
- Überprüfung der Ergebnisse: Nach Abschluss der Änderungen überprüft der Agent, ob diese korrekt sind, und versucht, eventuelle Fehler zu beheben.
- Abschluss der Aufgabe: Wenn der Agent mit den Änderungen zufrieden ist, fasst er die vorgenommenen Modifikationen zusammen.
5.2 Model Context Protocol (MCP), Cursor Agent und Figma-Integration
Model Context Protocol (MCP) fungiert als Plugin-System für Cursor \({\color{green}\text{[12]}}\) und ermöglicht die Erweiterung der Fähigkeiten des Agenten durch die Verbindung mit verschiedenen Datenquellen und Werkzeugen über standardisierte Schnittstellen.
MCP folgt einer Client-Server-Architektur, bei der eine Host-Anwendung mit mehreren Servern verbunden werden kann. Cursor unterstützt zwei Transporttypen für MCP-Server:
- stdio Transport: Läuft auf dem lokalen Computer, wird automatisch von Cursor verwaltet und kommuniziert direkt über stdout.
- SSE Transport: Kann lokal oder remote ausgeführt werden, wird vom Benutzer verwaltet und kommuniziert über das Netzwerk.
Die MCP-Konfiguration verwendet ein JSON-Format und kann an zwei Stellen platziert werden:
- Projektspezifische Konfiguration: In einer
~/.cursor/mcp.json-Datei im Home-Verzeichnis für Tools, die in allen Cursor-Workspaces verfügbar sein sollen. - Globale Konfiguration: In einer
~/.cursor/mcp.json-Datei im Home-Verzeichnis für Tools, die in allen Cursor-Workspaces verfügbar sein sollen.
Die Integration von Figma und Cursor über MCP ermöglicht es KI-Assistenten, mit Figma-Dateien zu interagieren. Es existieren mehrere MCP-Server für die Figma-Integration:
- Framelink Figma MCP: Dieser Server ist speziell für die Verwendung mit Cursor konzipiert und übersetzt die Antworten der Figma-API so, dass nur die relevantesten Layout- und Styling-Informationen an das Modell weitergegeben werden [].
- Cursor Talk to Figma MCP: Implementiert eine MCP-Integration zwischen Cursor AI und Figma, die es Cursor ermöglicht, Designs zu lesen und programmatisch zu ändern.
5.3 OpenHands: Open-Source-Alternative mit flexibler LLM-Integration
OpenHands \({\color{green}\text{[15]}}\) ist eine fortschrittliche Open-Source-Plattform für KI-gestützte Softwareentwicklung, die sich seit ihrer Entstehung erheblich weiterentwickelt hat. Es ist konzipiert, um generalisierte KI-Agenten zu erstellen und einzusetzen, die Aufgaben ähnlich wie menschliche Entwickler ausführen können, einschließlich der Modifikation von Code, der Ausführung von Befehlen, dem Browsen im Web und dem Aufrufen von APIs.
OpenHands ist im Wesentlichen eine Open-Source-Alternative zu proprietären KI-Entwicklungswerkzeugen wie Devin, ohne die damit verbundenen hohen Kosten. Alles, was Benutzer tun müssen, ist, eine Verbindung zu Anthropic oder OpenAI herzustellen, um auf ein state-of-the-art-Modell zuzugreifen; der Rest wird von der OpenHands-Anwendung verwaltet.
OpenHands-Agenten verfügen über die Fähigkeit, Code im Kontext eines bestehenden Projekts zu lesen, zu verstehen und zu verändern. Unter Nutzung des gewählten Large Language Models (LLM) analysiert der Agent die Codebasis, versteht die Abhängigkeiten zwischen Dateien und Funktionen und implementiert gezielte Änderungen basierend auf Benutzeraufforderungen.
Die Kernfunktionalitäten von OpenHands umfassen:
- Intelligente Code-Modifikation: Agenten können Code lesen, verstehen und im Kontext eines bestehenden Projekts ändern.
- Sichere Befehlsausführung: OpenHands kann Shell-Befehle (wie npm install, python manage.py runserver, git commit, ls, grep und andere) in einer geschützten, isolierten Sandbox-Umgebung ausführen.
- Integriertes Web-Browsing: Die Agenten können autonom im Web browsen, um Informationen zu recherchieren, die für die Erfüllung ihrer Aufgaben erforderlich sind.
- API-Interaktion: OpenHands-Agenten können mit externen APIs interagieren, um Daten abzurufen, Updates an andere Systeme zu senden oder Workflows zu orchestrieren, die verschiedene Tools umfassen.
- Dateisystem-Management: Agenten haben die Berechtigung, Dateien und Verzeichnisse innerhalb ihres zugewiesenen Arbeitsbereichs zu erstellen, zu lesen, zu schreiben und zu löschen.
5.3.1 TheAgentCompany: Benchmark für KI-Agenten in realitätsnahen Arbeitsszenarien
Mit dem rasanten Fortschritt bei Large Language Models (LLMs) ist die Entwicklung autonomer Agenten in der Softwareentwicklung ein zentrales Forschungsthema geworden. Ein besonders bedeutender Beitrag zur Evaluation solcher Agenten ist TheAgentCompany \({\color{green}\text{[16]}}\), ein offenes Benchmarking-Framework, das von der Carnegie Mellon University in Zusammenarbeit mit unabhängigen Forschern entwickelt wurde. Es bietet eine realitätsnahe, reproduzierbare Testumgebung zur Bewertung der Leistungsfähigkeit von LLM-Agenten bei beruflichen Aufgaben.
5.3.1.1 Motivation und Zielsetzung
Während viele Benchmarks synthetisch oder domänenspezifisch (z. B. reines Codieren) sind, deckt TheAgentCompany ein breites Spektrum realitätsnaher Tätigkeiten ab, wie sie typischerweise in einem Softwareunternehmen auftreten. Dazu gehören u. a.:
- Softwareentwicklung
- Projektmanagement
- Datenanalyse
- Human Resources (HR)
- Administration
- Finanzaufgaben
Die Umgebung simuliert ein digitales Start-up mit gängigen Tools (GitLab, Rocket.Chat, OwnCloud etc.), wobei der Agent über Terminal, Browser und IPython mit der Umgebung interagiert.
| Komponente | Beschreibung |
|---|---|
| Plattformen | GitLab, OwnCloud, Rocket.Chat, Plane |
| Schnittstellen | Webbrowser (Playwright), Bash-Terminal, Jupyter/IPython |
| Kommunikation | Simulierte Kolleg:innen über LLM (Claude 3.5 Sonnet) via Rocket.Chat |
| Ausführung | Sandbox-Umgebung via Docker (vollständig isoliert und reproduzierbar) |
| Aufgabenanzahl | 175 realitätsnahe Aufgaben aus 7 Berufsrollen |
| Bewertung | Checkpoint-basiert mit Teilpunktvergabe (automatisch oder durch LLM-Evaluatoren) |
Überblick über die Komponenten der Benchmarking-Umgebung von TheAgentCompany. Diese umfasst gängige Werkzeuge aus der Softwareentwicklung, verschiedene Agenten-Schnittstellen und realitätsnahe Simulationsbedingungen.
| Modell | Erfolgsquote | Teilerfüllung | Durchschnittliche Schritte | Durchschnittliche Kosten |
|---|---|---|---|---|
| Claude-3.5-Sonnet | 24,0 % | 34,4 % | 29,17 | $6,34 |
| Gemini-2.0-Flash | 11,4 % | 19,0 % | 39,85 | $0,79 |
| GPT-4o | 8,6 % | 16,7 % | 14,55 | $1,29 |
| Llama-3.1 (405B, open) | 7,4 % | 14,1 % | 22,95 | $3,21 |
Vergleich der Leistungsfähigkeit ausgewählter LLM-basierter Agenten bei der Ausführung realitätsnaher Aufgaben in TheAgentCompany. Bewertet werden Erfolgsquote (vollständige Aufgabenlösung), Teilerfüllung, durchschnittliche Schrittanzahl und geschätzte API-Kosten. Die Teilerfüllung bewertet auch partielle Aufgabenerfolge mittels gewichteter Checkpoints.
| Plattform | Claude-3.5 | GPT-4o | Llama-3.1 (405B) |
|---|---|---|---|
| GitLab | 31,0 % | 11,3 % | 5,6 % |
| Rocket.Chat | 21,5 % | 5,1 % | 8,9 % |
| OwnCloud | 10,0 % | 1,4 % | 0,0 % |
| Plane (PM-Tool) | 41,2 % | 23,5 % | 29,4 % |
Erfolgsraten ausgewählter LLM-Modelle bei Aufgaben, die jeweils eine der vier Hauptplattformen erfordern (GitLab, Rocket.Chat, OwnCloud und Plane). Die Ergebnisse zeigen deutliche Unterschiede in der Plattformtauglichkeit der Agenten.
5.3.1.2 Erkenntnisse
Softwareentwicklung vs. “einfache” Aufgaben
Während menschlich betrachtet SDE-Aufgaben (Software Development Engineering) als schwieriger gelten, schneiden LLM-Agenten in diesen Aufgaben besser ab als bei scheinbar einfachen Tätigkeiten wie Tabellenverarbeitung oder HR-Screenings. Dies liegt vermutlich daran, dass viele Modelle stark auf Code-Daten trainiert wurden.Herausforderungen bei Interaktion & UI
Besonders schwach sind die Agenten bei Aufgaben, die komplexe Web-UIs (z. B. OwnCloud) oder soziale Interaktionen (z. B. Gespräche mit Kolleg:innen) erfordern.Bezug zu OpenHands und Cursor Agent
Die Agenten in TheAgentCompany basieren auf dem OpenHands-Agentengerüst, was die Vielseitigkeit dieser Open-Source-Plattform unter Beweis stellt. Die Cursor Agent Architektur zeigt ebenfalls Ähnlichkeiten – insbesondere in der autonomen Ausführung und mehrstufigen Planung von Aufgaben.
TheAgentCompany bietet eine robuste, praxisnahe Testumgebung zur objektiven Evaluation moderner LLM-Agenten. Die Integration realitätsnaher Werkzeuge, Aufgaben und Kommunikationsflüsse liefert wertvolle Einblicke in den aktuellen Stand der Autonomie von KI-Systemen am Arbeitsplatz. Während einfache Entwicklungsaufgaben teils erfolgreich abgeschlossen werden, zeigen sich große Lücken bei sozialen, administrativen und webbasierten Aufgaben – was gezielte Optimierungspotenziale für die Weiterentwicklung von KI-Agenten offenbart.
6 Quellen
- AI Agents: Evolution, Architecture, and Real-World Applications
- An Interactive Agent Foundation Model
- Agent Laboratory: Using LLM Agents as Research Assistants
- Generative Agents: Interactive Simulacra of Human Behavior
- AI Agents That Matter
- Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
- Agents and tools. Model Context Protocol (MCP)
- Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
- Ollama
- Ollama Documentation
- Cursor Agent Mode
- Cursor MCP
- Framelink Figma MCP (GitHub)
- Cursor Talk to Figma MCP (GitHub)
- OpenHands (GitHub)
- THEAGENTCOMPANY: BENCHMARKING LLM AGENTS ON CONSEQUENTIAL REAL WORLD TASKS