Versuch 6: CICD
1 Der momentane Deploy-Prozess
Aktuell erfolgt das Deployment unseres Quarto-Projekts auf den Webserver der THA noch manuell. Dafür wurde ein Python-Skript namens deploy_rendered_quarto.py entwickelt, das zwei zentrale Aufgaben übernimmt: das Rendern des Projekts und das Hochladen auf den Server.
1.1 Was macht das Skript?
Das Skript übernimmt zwei Hauptaufgaben:
Rendern des Quarto-Projekts
Das Projekt wird lokal mit dem Befehlquarto rendergerendert und in statische HTML-Dateien umgewandelt.Upload per SFTP
Der generierte Inhalt aus dem Ordner_site/wird per SFTP in das Webverzeichnis/www/dva03/auf dem THA-Server übertragen. Die Verbindung erfolgt dabei sicher über SSH mit einem im SSH-Agent geladenen Schlüssel.
Der ganze Prozess wird lokal mit folgendem Befehl gestartet:
python deploy_rendered_quarto.py /pfad/zum/projektDer komplette Python-Code für das manuelle Deployment befindet sich in unserem GitLab-Repository unter:
versuch6/deploy_rendered_quarto.py
1.2 Probleme bei diesem Ansatz
- Das Deployment muss manuell ausgeführt werden
- Es läuft nur auf einem einzelnen lokalen Rechner, andere Teammitglieder können es nicht einfach übernehmen
- Änderungen im Git-Repository führen nicht automatisch zu einem neuen Deployment
- Es gibt keine Protokollierung oder Nachvollziehbarkeit im Repository selbst
1.3 Nächstes Ziel
Ziel ist es, diesen Prozess zu automatisieren. Geplant ist eine GitLab CI/CD Pipeline, die automatisch beim Push ins Repository den Build ausführt und das fertige Projekt auf den Webserver deployed.
2 Projektsetup: Dienstkonto und virtuelle Maschine
Für den automatisierten Deploy-Prozess wurde beim Rechenzentrum der Hochschule ein Dienstkonto sowie eine eigene virtuelle Maschine (VM) beantragt und eingerichtet.
2.1 Beantragung
Folgende Ressourcen wurden vom RZ bereitgestellt:
Dienstkonto:
dva03
Ein technisches Benutzerkonto, das unabhängig vom persönlichen Hochschul-Login funktioniert. Dieses Konto wird für den Zugriff auf das Webverzeichnis sowie für SSH-Zugriffe auf die VM verwendet.Virtuelle Maschine:
prakdva03.informatik.tha.de
Eine eigene Debian-basierte VM im THA-Netz. Sie dient als zentrale Instanz für GitLab Runner und Deployment-Prozesse.
2.2 Warum das nötig war
2.2.1 Trennung von persönlichem und technischem Zugriff
Auch wenn das Projekt nur von unserem festen Viererteam umgesetzt wird, ist es sinnvoll, das Dienstkonto dva03 zu nutzen. Es sorgt dafür, dass:
- keine persönlichen THA-Zugangsdaten im Deployment verwendet werden
- das Projekt von allen im Team gleichermaßen bearbeitet und deployed werden kann
- persönliche Accounts sauber vom Projektsetup getrennt bleiben
So haben alle denselben Zugang, und das Deployment läuft unabhängig davon, wer es gerade ausführt.
2.2.2 Warum eine eigene VM?
Die Debian-VM unter prakdva03.informatik.tha.de dient als zentrale Umgebung für alles, was mit dem Deployment zu tun hat:
Unabhängigkeit vom lokalen Rechner
Wir müssen das Deployment nicht mehr lokal auf unseren eigenen Rechnern ausführen.Gemeinsame Arbeitsumgebung
Auf der VM läuft alles zentral und einheitlich. z.B. der GitLab Runner und der Zugriff auf das Webverzeichnis/www/dva03/.
Die VM ist also unsere stabile, zentrale Anlaufstelle für alles, was mit automatisiertem Deployment zu tun hat.
Durch die Kombination aus einem technischen Benutzerkonto (dva03) und einer dedizierten VM (prakdva03.informatik.tha.de) wurde eine saubere, sichere Infrastruktur für automatisiertes Deployment geschaffen.
3 Pipeline Theoretische Grundlagen
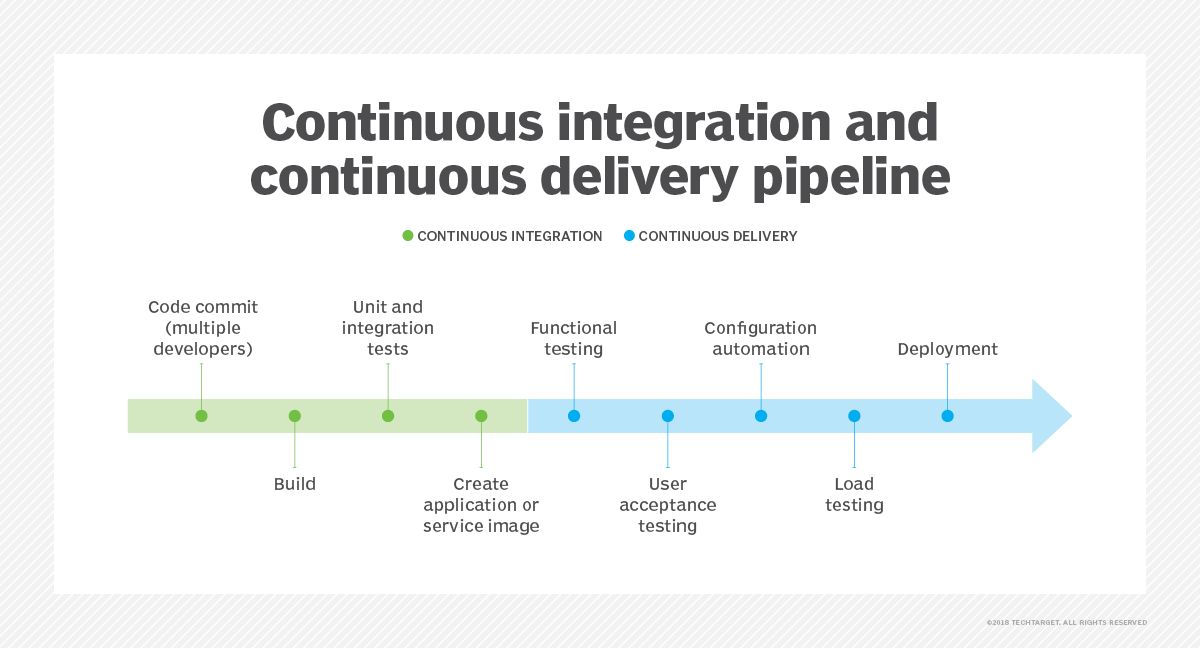
Eine Pipeline ist ein Softwaretool um Anwendungen effizienter zu bauen, testen und zu delivern und deployen. Eine Pipeline besteht aus N Stages, die jeweils Jobs beinhalten. Stages dienen dazu, Jobs logisch zu gruppieren und in separate Stufen zu unterteilen. So können zum Beispiel alle Jobs, die zum Testen benötigt werden, zusammen gruppiert werden. Ein Job definiert eine Aufgabe und kann verschiedene Aktionen umfassen, wie zum Beispiel zum Bauen (quarto make), Testen (pytest/junit/…), Deployen (scp/ssh …) und vieles mehr.
Eine Pipeline beinhaltet also eine Kette von Stages die nacheinander ausgeführt werden. Bevor die nächste Stage durchlaufen wird muss die vorherige Stage erfolgreich beendet worden sein.
Eine Pipeline kann in 2 Abschnitte unterteilt werden.
- CI = Continuous Integration = Durchgehendes integrieren von neuem Code in die Application durch z.B. automatisierte Testfälle in der Pipeline
- CD = Continuous Delivery = Durchgehendes Ausliefern von neuem Code durch automatisiertes Ausführen von Skripts nach bestandenen Testfällen
Vorteile von Pipelines:
- Effizienter Entwicklungsprozess
- Verbesserte Codequalität durch automatisierte Tests
- Automatisierte Sourcing und Delivery/Deployment Prozesse
- Geregelter Zeitplan durch automatisiertes Ausführen der Pipelinestages
- Konsistenz
4 Runners
Ein Runner ist ein ausführendes Programm, das Anweisungen vom CI/CD-System (z. B. GitLab CI, GitHub Actions, Jenkins) entgegennimmt und die dazugehörigen Aufgaben in einer definierten Umgebung ausführt. ## Aufgaben eines Runners
- Ausführen von Builds (z. B. Kompilierung des Codes)
- Starten von Tests
- Deployment von Anwendungen
- Hochladen von Artefakten oder Berichten
4.1 Typen von Runnern
| Typ | Beschreibung |
|---|---|
| Shared Runner | Wird von mehreren Projekten gemeinsam genutzt |
| Specific Runner | Nur für ein bestimmtes Projekt oder eine Projektgruppe verfügbar |
| Self-hosted Runner | Läuft auf eigener Infrastruktur (z. B. eigener Server, VM) |
| Cloud Runner | Läuft in der Cloud, z. B. bei GitHub oder GitLab SaaS-Angeboten |
4.2 Vorteile der Verwendung von Runnern
- Skalierbarkeit: Jobs können parallel auf mehreren Runnern laufen.
- Flexibilität: Runner können für spezifische Anforderungen angepasst werden (z. B. spezielle Software).
- Trennung von Steuerung und Ausführung: Der CI/CD-Server plant und koordiniert, der Runner führt aus.
4.3 Beispiel: GitLab Runner
job_build:
script:
- make build
tags:
- linux5 Unsere Pipeline
5.1 Anforderungen
Unsere Pipeline muss (vorerst) folgende Aufgaben übernehmen: 1. Die neu gepushten Quarto Files in HTML Files umwandeln 2. Die erstellten HTML Files auf unsere Website deployen
5.2 Erster Entwurf
Um dies zu erreichen haben wir einen ersten Entwurf erstellt. Dabei wurden alle erforderlichen Schritte in eine Stage geschrieben. Da es sich hierbei nur um einen vorläufigen Entwurf handelt wird die Sinnhaftigkeit von einer zusammengefassten Stage vorerst ignoriert.
Um Quarto Files in HTML umzuwandeln, muss zuerst Quarto installiert werden. Anschließend wird mit “quarto render” die Umwandlung durchgeführt. Um im Anschluss noch das Ergebnis auf die Website zu deployen muss zuerst der im Gitlab als Variable hinterlegte SSH Key gefetched werden. Anschließend wird mit scp das _site/ directory hochgeladen und somit die Website deployed.
stages:
- deploy
deploy-quarto:
stage: deploy
script:
- cd quarto
- curl -LO https://github.com/quarto-dev/quarto-cli/releases/download/v1.7.22/quarto-1.7.22-linux-amd64.deb
- sudo apt-get install -y ./quarto-1.7.22-linux-amd64.deb
- quarto render
- mkdir -p ~/.ssh
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' > ~/.ssh/id_rsa
- chmod 600 ~/.ssh/id_rsa
- ssh-keyscan -H login.rz.hs-augsburg.de >> ~/.ssh/known_hosts
- scp -i ~/.ssh/id_rsa -r _site/* dva03@login.rz.hs-augsburg.de:/www/dva03/
#5.3 Aktuelle Pipeline
Nach sämtlichen Bugfixes und Verbesserungen wurde folgender finaler Entwurf erstellt und ist aktuell in Verwendung:
stages:
- quarto
- deploy
quarto:
stage: quarto
script:
- cd quarto
- quarto render
artifacts:
paths:
- "quarto/_site/"
deploy:
stage: deploy
script:
- cd quarto
- mkdir -p ~/.ssh
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' > ~/.ssh/id_rsa
- chmod 600 ~/.ssh/id_rsa
- scp -v -i ~/.ssh/id_rsa -r _site/* dva03@login.rz.hs-augsburg.de:/www/dva03/Im Vergleich zum ersten Entwurf gibt es folgende Änderungen:
- Aufteilung in mehrere Stages, Erhalt der Dateien durch artifacts
- Quarto Installation wurde entfernt
- Hinzufügen der -v flag beim scp command um debug output zu erhalten
Fazit:
Da bereits in Woche 1 das Thema Ansible behandelt wurde, war das Erstellen einer CI/CD Pipeline kein großer Aufwand. Der Syntaxunterschied zwischen Ansible Playbook und CI/CD Pipeline ist sehr klein. So benutzen beide zum Beispiel yaml Dateien und es werden u.a. bash commands ausgeführt.
6 Einrichtung des GitLab Runners auf der VM
Zur Automatisierung unserer CI/CD-Pipeline haben wir auf der VM prakdva03.informatik.tha.de einen GitLab Runner installiert und mit unserem Projekt verbunden. Dieser Runner führt die Befehle aus der .gitlab-ci.yml automatisch bei jedem Push ins Repository aus.
6.1 Einrichtungsschritte
6.1.1 1. Runner im GitLab-Projekt erstellen
Im Projekt unter
Settings > CI/CD > Runners
wurde über die Schaltfläche “New project runner” ein neuer Runner erstellt. Dabei wurde ein Authentifizierungs-Token generiert, das zur einmaligen Registrierung verwendet wird.
6.1.2 2. GitLab Runner auf der VM installieren
Nach dem Login auf der VM als Benutzer yazan:
ssh yazan@prakdva03.informatik.tha.dewurde der GitLab Runner wie folgt installiert:
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash
sudo apt install gitlab-runner6.1.3 3. Runner registrieren
Die Registrierung des Runners erfolgte mit dem zuvor generierten Token:
sudo gitlab-runner register \
--url https://gitlab.hs-augsburg.de/ \
--token <TOKEN> \
--executor shell \
--description "prakdva03-runner"Der Authentifizierungstoken beginnt mit
glrt-...und wird aus Sicherheitsgründen nur einmal angezeigt.
6.1.4 4. Runner starten und Status prüfen
Nach erfolgreicher Registrierung wurde der Runner gestartet:
sudo gitlab-runner startDer Status kann wie folgt überprüft werden:
sudo gitlab-runner statusIn GitLab wird der Runner nun unter “Project runners” als aktiv angezeigt.
7 CI/CD-Tools
In der heutigen schnelllebigen Welt der Softwareentwicklung haben sich CI/CD-Tools als unverzichtbare Komponenten etabliert, die den Entwicklungsprozess beschleunigen, die Softwarequalität verbessern und die Zusammenarbeit zwischen Entwicklungsteams fördern. Diese Studienarbeit bietet eine tiefgreifende Analyse verschiedener CI/CD-Tools, ihrer Funktionalitäten, Stärken und Schwächen sowie Einsatzmöglichkeiten in unterschiedlichen Kontexten.
7.1 Jenkins: Anpassbare Pionier
Jenkins ist ein Open-Source-Automatisierungsserver, der häufig im Bereich der Softwareentwicklung verwendet wird, um Continuous Integration (CI) und Continuous Delivery (CD) zu implementieren. Es ermöglicht Entwicklern, Software schneller und zuverlässiger zu erstellen, zu testen und bereitzustellen. Jenkins ist ein CI/CD-Tool, das in Java geschrieben wurde und die Automatisierung von Software-Workflows unterstützt. Es hilft dabei, Fehler frühzeitig zu erkennen und die Qualität des Codes zu verbessern \({\color{green}\text{[1]}}\).
Das System besteht aus einem Master-Server und beliebig vielen Build-Agenten, die die eigentliche Arbeit erledigen. Diese Architektur ermöglicht es, Workloads über mehrere Maschinen zu verteilen und damit die Ausführungsgeschwindigkeit von Jobs zu erhöhen.
Jenkins zeichnet sich besonders durch sein umfangreiches Plugin-Ökosystem aus, das mehr als 1.800 Plugins umfasst und nahezu unbegrenzte Anpassungs- und Integrationsmöglichkeiten bietet. Die Konfiguration erfolgt entweder über die webbasierte Benutzeroberfläche oder durch die Definition von Pipelines als Code mittels der “Jenkinsfile”-Syntax, die auf Groovy basiert
Kernkonzepte
Pipeline: Eine Jenkins-Pipeline ist ein Workflow, der aus mehreren Schritten besteht, um Anwendungen zu bauen, testen und bereitzustellen. Sie wird in einer Datei namens Jenkinsfile definiert \({\color{green}\text{[2, 3]}}\).
Plugins: Jenkins verfügt über eine umfangreiche Plugin-Architektur, die es ermöglicht, externe Tools wie Git, Docker oder Kubernetes zu integrieren \({\color{green}\text{[4]}}\).
Hauptkomponenten
Jenkins Master: Der zentrale Server koordiniert alle Aufgaben, überwacht Jobs und verwaltet die Konfigurationen \({\color{green}\text{[4]}}\).
Agents: Diese führen die Aufgaben aus, die vom Master zugewiesen werden. Die Kommunikation erfolgt über sichere Kanäle wie SSH oder JNLP.
Build Executors: Prozesse auf den Agents, die die eigentliche Arbeit wie das Bauen oder Testen von Code übernehmen.
Workflow
Entwickler committen Änderungen in ein Repository.
Jenkins erkennt diese Änderungen (Pull-/Push-Modus) und startet einen neuen Build.
Nach erfolgreichem Build werden automatisierte Tests durchgeführt.
Falls keine Fehler auftreten, wird der Code in die Produktionsumgebung bereitgestellt
Beispiel eines Jenkinsfile:
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building...'
}
}
stage('Test') {
steps {
echo 'Testing...'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
}
}
}
}Dieses Beispiel zeigt eine einfache Pipeline mit den Stufen Build, Test und Deploy
7.2 GitLab CI/CD: Integrierte Lösung
GitLab CI/CD ist tief in die GitLab-Plattform integriert und Teil eines umfassenden DevOps-Ökosystems. Das System basiert auf einer Runner-Architektur, bei der dezentrale Runner-Instanzen die eigentlichen CI/CD-Jobs ausführen. Diese Runner können sowohl in der Cloud als auch on-premises betrieben werden und unterstützen verschiedene Ausführungsumgebungen wie Docker-Container oder virtuelle Maschinen.
GitLab CI/CD definiert Pipelines durch eine YAML-basierte Konfigurationsdatei (.gitlab-ci.yml), die im Wurzelverzeichnis des Repositories gespeichert wird. Eine besondere Stärke ist die nahtlose Integration mit anderen GitLab-Funktionen wie Issue-Tracking, Container-Registry und Sicherheitsscans.
Die Auto DevOps-Funktion kann automatisch Pipelines basierend auf dem Projekttyp erstellen, was den Einstieg erleichtert und Best Practices fördert. Zudem bietet GitLab CI/CD integrierte Sicherheitsfunktionen wie SAST (Static Application Security Testing), DAST (Dynamic Application Security Testing) und Dependency Scanning.
Kernkonzepte
Pipelines: Eine Pipeline ist eine Abfolge von Stufen (Stages) und Jobs, die Aufgaben wie Kompilieren, Testen oder Bereitstellen ausführen. Pipelines werden in einer .gitlab-ci.yml-Datei definiert \({\color{green}\text{[5, 6]}}\).
Jobs: Einzelne Aufgaben innerhalb einer Pipeline, die unabhängig voneinander ausgeführt werden können.
Stages: Gruppieren verwandter Jobs; z. B. build, test, deploy. Stages werden sequenziell ausgeführt, während Jobs innerhalb einer Stage parallel laufen können.
Runner: Agenten, die Jobs ausführen. Sie können lokal, in der Cloud oder selbst gehostet sein \({\color{green}\text{[7, 8]}}\).
Workflow
Code Commit: Entwickler pushen Änderungen in das GitLab-Repository.
Pipeline Trigger: Eine Pipeline wird automatisch durch Ereignisse wie Commits oder Merge Requests ausgelöst.
Runner-Auswahl: GitLab weist verfügbare Runner zu, um Jobs auszuführen.
Job-Ausführung: Runner führen die definierten Aufgaben aus (z. B. Tests oder Deployments).
Statusüberwachung: Der Fortschritt und Status jedes Jobs wird in der GitLab-Oberfläche angezeigt
Technische Komponenten
GitLab Server: Zentrale Verwaltung der Pipelines und Kommunikation mit Runners.
Repositories: Code-Basis, die Änderungen speichert und Pipelines auslöst.
YAML-Konfiguration: Die .gitlab-ci.yml-Datei definiert den Ablauf der Pipeline.
Artefakte und Caching: Zwischenergebnisse wie Build-Artefakte können gespeichert und wiederverwendet werden, um Laufzeiten zu optimieren
Schritte zur Einrichtung
Eine
.gitlab-ci.ymlDatei erstellenDie Stages definieren
stages:
- build
- test
- deploy- Die Jobs hinzufügen
build_job:
stage: build
script:
- echo "Building the application"
test_job:
stage: test
script:
- echo "Running tests"
deploy_job:
stage: deploy
script:
- echo "Deploying to production" - Runner aktivieren, um die Jobs auszuführen
7.3 CircleCI:: Cloud-native Lösung
CircleCI ist eine vollständig cloud-native CI/CD-Plattform, die sich auf Geschwindigkeit, einfache Bedienung und nahtlose Docker-Integration fokussiert. Im Gegensatz zu selbst-gehosteten Lösungen wie Jenkins oder GitLab CI/CD entfallen eigene Server-Installationen: CircleCI stellt die Infrastruktur in der Cloud bereit, kann aber auch in einer Enterprise-Edition on-premises betrieben werden.
Die Konfiguration erfolgt über eine YAML-Datei namens .circleci/config.yml, die im Root-Verzeichnis des Projekts liegt. CircleCI nutzt Docker-Container als Standard-Execution-Environment, wodurch Builds isoliert und reproduzierbar werden. Parallele Builds und intelligente Caching-Mechanismen reduzieren die Laufzeit erheblich.
Kernkonzepte:
Jobs - Ein Job ist eine Einheit, die eine Reihe von Commands ausführt (z. B. Kompilieren, Testen). Jeder Job läuft in einem dedizierten Docker-Container oder in einer virtuellen Maschine (je nach Konfiguration).
Workflows - Workflows definieren die Reihenfolge, in der Jobs ausgeführt werden (seriell oder parallel). Ein Workflow kann beispielsweise mehrere build-Jobs parallel starten, danach test-Jobs und abschließend deploy. Workflows definieren die Reihenfolge, in der Jobs ausgeführt werden (seriell oder parallel). Ein Workflow kann beispielsweise mehrere build-Jobs parallel starten, danach test-Jobs und abschließend deploy.
Executor - CircleCI unterstützt drei Executor-Typen:
- Docker - Standard, leichtgewichtig, Container-basiert.
- Machine - Vollwertige virtuelle Maschine, notwendig, wenn spezielle Priviliegien oder spezielle Umgebungen benötigt werden.
- MacOS - Für iOS-/macOS-Builds.
Caching - Durch den Einsatz von Workspaces und Caching-Strategien (z. B. Caching der node_modules-Ordner oder von Docker-Layern) lassen sich wiederverwendbare Artefakte zwischen Jobs speichern und damit Build-Zeiten senken.
Orb-Ecosystem - CircleCI Orbs sind vorgefertigte, wiederverwendbare Bibliotheken, die Konfigurations-Snippets für gängige Tools (z. B. AWS, Docker, Slack, Kubernetes) enthalten. Orbs beschleunigen Initialsetup und standardisieren CI/CD-Abläufe.
Workflow:
Code Commit - Entwickler pushen Änderungen in ein Git-Repository (GitHub, Bitbucket oder GitLab).
Pipeline Trigger - CircleCI reagiert auf Commits und startet automatisch definierte Jobs.
Job-Ausführung - Jeder Job wird in einem Docker-Container (oder anderem Executor) ausgeführt. Parallele Builds sind einfach konfigurierbar, indem man Jobs in einem Workflow nebeneinander anordnet.
Caching und Workspaces - Ergebnisse von Schritten (z. B. installierte Abhängigkeiten) werden zwischengespeichert und stehen späteren Jobs zur Verfügung.
Deployment - Nach erfolgreichem Abschluss von Build- und Test-Jobs können Deployments (z. B. Ansible-Scripts, Kubernetes Deployments, oder Cloud-Provider-Befehle) erfolgen.
Reporting - CircleCI stellt ausführliche Logs, Metriken und Visualisierungen zur Verfügung, um Build-Zeiten, Testabdeckung und Ressourcenauslastung zu überwachen.
7.4 Terraform: IaC-Spezialist
Terraform ist ein Open-Source-Tool von HashiCorp \({\color{green}\text{[9]}}\), das den Paradigmenwechsel hin zu „Infrastructure as Code“ (IaC) ermöglicht. Mit Terraform beschreiben DevOps-Teams Infrastruktur-Ressourcen deklarativ in einer auf HashiCorp Configuration Language (HCL) basierenden Syntax. Anstatt Infrastruktur manuell über Cloud-Konsolen aufzubauen, definiert man Ports, virtuelle Maschinen, Datenbanken usw. in Code und lässt Terraform automatisch die notwendigen API-Aufrufe an Cloud-Provider (z. B. AWS, Azure, Google Cloud) generieren.
Kernkonzepte:
Resources - Dies sind konkrete Infrastruktur-Objekte, wie z. B. aws_instance, google_storage_bucket oder azurerm_virtual_network. Jede Resource beschreibt gewünschte Attribute (z. B. Instanztyp, Region, Tags).
Providers - Provider sind Plugins, die Terraform in die Lage versetzen, mit Cloud-Providern oder anderen APIs zu kommunizieren. Beispiele sind hashicorp/aws, hashicorp/azurerm und hashicorp/google.
Module - Module bündeln mehrere zusammengehörige Ressourcen zu wiederverwendbaren Einheiten. So lassen sich komplexe Infrastrukturen als abstrahierte Komponenten (etwa ein komplettes VPC-Setup oder eine Kubernetes-Umgebung) organisieren und versionieren.
State - Terraform speichert Informationen über die aktuell verwaltete Infrastruktur in einer State-Datei (standardmäßig terraform.tfstate). Der State dient dazu, vorherige Deployments mit der aktuellen Konfiguration abzugleichen und nur notwendige Änderungen durchzuführen.
Workspaces - Mit Workspaces lassen sich mehrere Zustände (z. B. für verschiedene Umgebungen wie Development, Staging und Production) verwalten. Jeder Workspace enthält eine eigene State-Datei.
Workflow:
Write (Plan) - Der Entwickler schreibt oder ändert HCL-Dateien und führt dann terraform plan aus. Terraform liest den aktuellen State, vergleicht ihn mit der gewünschten Konfiguration und zeigt die geplanten Aktionen (Erstellen, Ändern, Löschen von Ressourcen) an.
Apply - Per terraform apply werden die im Plan gezeigten Änderungen umgesetzt. Terraform kommuniziert mit den relevanten Cloud-APIs, um die Infrastruktur an den gewünschten Endzustand anzupassen.
Destroy - Mit terraform destroy kann die komplette Infrastruktur wieder entfernt werden. Dies ist besonders nützlich für zeitlich begrenzte Testumgebungen.
State-Management - States sollten nicht lokal im Projektverzeichnis liegen, sondern in einem Remote Backend (z. B. S3 mit DynamoDB-Locking, Terraform Cloud/Enterprise, Google Cloud Storage). So verhindern mehrere Teammitglieder Konflikte und stellen sicher, dass immer die aktuelle State-Datei verwendet wird.
7.5 Vergleichende Analyse
| Tool | Vorteile | Nachteile |
|---|---|---|
| Jenkins | Großes Plugin-Ökosystem, Pipeline as Code, Plattform- und Sprachunabhängigkeit | Hohe Komplexität bei Setup und Wartung, Ressourcenintensiv in großen Umgebungen, Veraltete UI |
| GitLab CI/CD | Integriertes DevSecOps & Issue-Tracking, Auto DevOps für schnelle Standard-Pipelines, Moderne UI | Kosten für Premium-/Ultimate-Pläne, Kein verschachteltes Staging, Artefakt-Handling erfordert Mehraufwand |
| Terraform | Deklaratives IaC, cloud-agnostisch, Modulares Design & Versionierung, Remote State-Backends | Steile Lernkurve für komplexe Konfigurationen, State Management (Drift, Locking) kann herausfordernd sein |
| CircleCI | Cloud-Native, sofort einsatzbereit, Docker-native Builds, Schnelle Parallelisierung & Caching, Orbs für Standard-Integrationen | Kostenintensiv ab hohem Ressourcenbedarf, Eingeschränkte On-Premise-Option (nur Enterprise), Weniger tiefgreifende Customization im Vergleich zu Jenkins |
8 Live Demo
9 DVA-Praktikum fertig :D
10 Referenzen
- What is Jenkins and How Does It Work? | Definition from TechTarget
- What is Jenkins? Key Concepts & Tutorial
- Jenkinsfile Template
- Jenkins Architecture Explained
- CI/CD pipelines
- Get started with GitLab CI/CD
- Tutorial: Create and run your first GitLab CI/CD pipeline
- GitLab CI/CD
- Managing Infrastructure as Code (IaC) With Terraform